
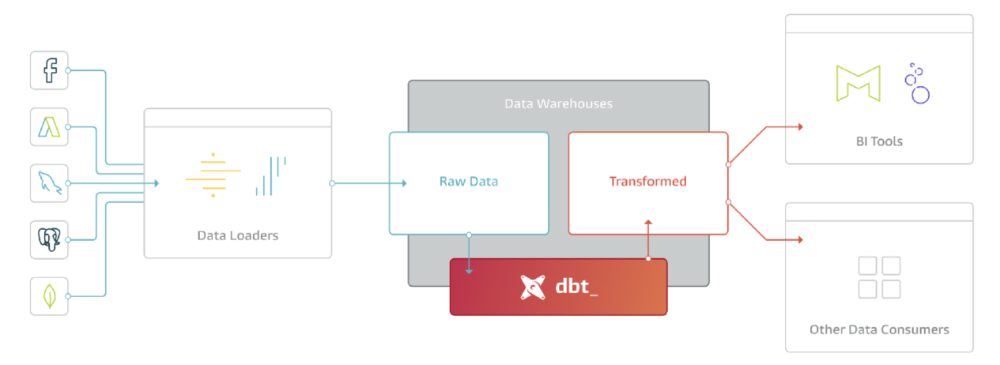
Notre premier billet sur le sujet nous a permis de présenter sommairement un workflow complet de traitement de données sur la plateforme DataTask. Ce dernier permet de récupérer de la donnée web analytics pour mettre à disposition des utilisateurs un dashboard relatif aux visites sur les sites.
L’objectif de ce billet est de s’intéresser plus en détail à la partie Transformation du workflow et plus particulièrement à l’outil DBT et à son intégration au sein de la plateforme DataTask.
DBT : qu’est ce que c’est ?
DBT (Data Build Tool) est un outil open source de transformation de données (T dans ETL ou ELT) au sein des datawarehouses (Snowflake, Bigquery, Redshift, Postgres).
Son utilisation repose sur des modèles écrits en langage SQL pour définir les transformations. Cela le rend facilement accessible au data analyste. Lors d’une exécution, les modèles sont matérialisés dans le datawarehouse sous forme de tables ou de vues.
Si la simplicité de DBT vient de l’utilisation du SQL, sa force est issue de l’association de ce dernier au langage de templating jinja. Cela va permettre, en autres, d’écrire du code beaucoup plus modulaire, d’utiliser des variables et des macros, d’ajouter des structures de contrôle (if, for, etc.).
Mais le premier apport de cette association est la possibilité de référencer les modèles entre eux en utilisant la fonction ref(). A l’aide de cette fonction, DBT va être en mesure de générer un graphe de dépendances (DAG) entre les modèles ce qui va déterminer automatiquement l’ordre d’exécution de chaque modèle.
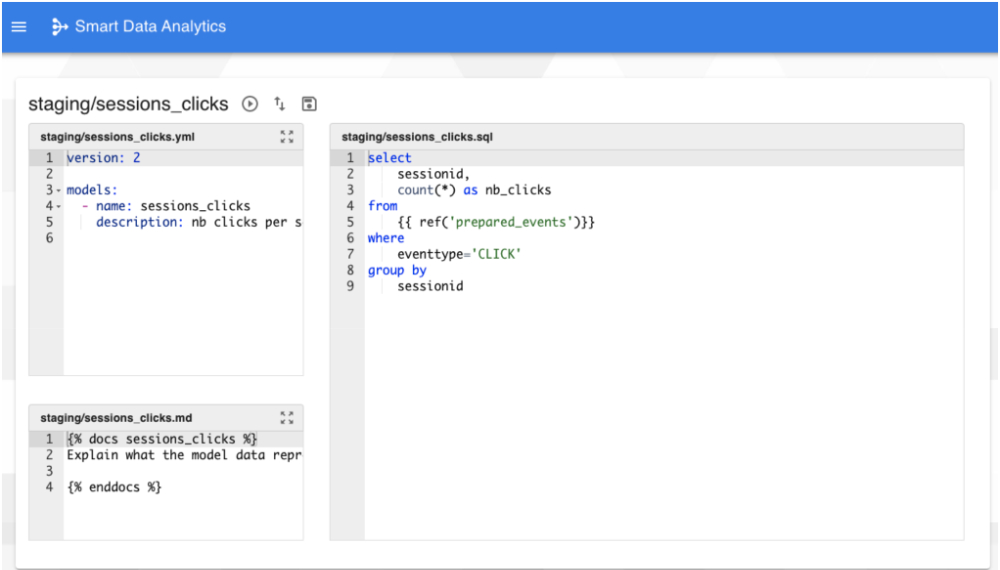
L’exemple suivant permet de définir un modèle sessions_clicks de transformation qui va déterminer le nombre de clics par session utilisateur
(sessions_clicks.sql) :
select
sessionid,
count(*) as nb_clicks
from
{{ ref('prepared_events')}}
where
eventtype='CLICK'
group by
sessionid
Ce modèle faisant référence au modèle prepared_events, DBT construit le dag suivant : prepared_events → sessions_clicks, ce qui lui permet de savoir qu’il faut exécuter prepared_events avant sessions_clicks.
DBT permet également d’associer de la métadonnée aux modèles à travers des fichiers yaml ce qui va lui apporter de nombreuses fonctionnalités supplémentaires notamment :
- la génération de la documentation,
- la définition de tests de validation de la donnée.
Ceci n’est qu’un aperçu très rapide des principales fonctionnalités de DBT, pour en savoir plus, vous pouvez vous référer à la documentation officielle très complète.
DBT dans Datatask
Si DBT est un outil très puissant et relativement simple d’utilisation, il s’avère que certains points peuvent être plus délicats à mettre en œuvre pour des personnes qui ne sont pas rompues au développement et aux architectures liées à la data :
- Outil en ligne de commande
- La gestion du code et de ses versions doit se faire dans l’outil de versioning de code GIT.
- L’installation et la configuration initiale doivent se faire sur le poste de l’utilisateur.
L’intégration Datatask va permettre de s’affranchir de toutes ces difficultés à travers la mise à disposition d’une interface graphique très simple nommée Smart Data Analytics.
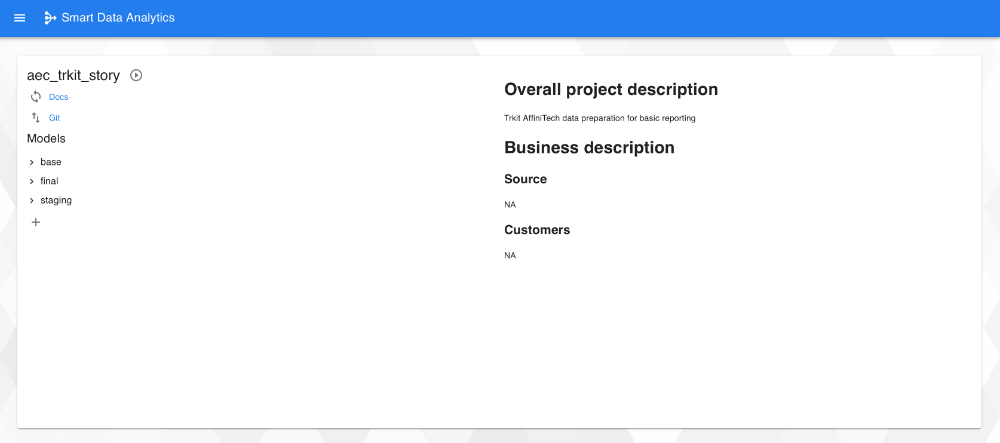
Cette interface va permettre de visualiser les informations relatives au projet ainsi que l’ensemble des modèles déjà configurés. Il est également possible de se synchroniser avec le dépôt GIT intégré à Datatask, de générer et d’accéder à la documentation ou de lancer n’importe quelle commande DBT.
La création du modèle sessions_clicks vu précédemment est alors très simple : l’ajout d’un modèle permet d’accéder à la page de configuration dédiée composée de 3 volets :
- Le volet principal contenant le code SQL/jinja
- Le volet de metadonnées (fichier yaml)
- Le volet de documentation (fichier md)
Chacun de ces volets est prérempli avec un template afin d’aider à la mise en place du modèle.
Il est alors possible de lancer la matérialisation de ce modèle avec l’ensemble de ses dépendances :
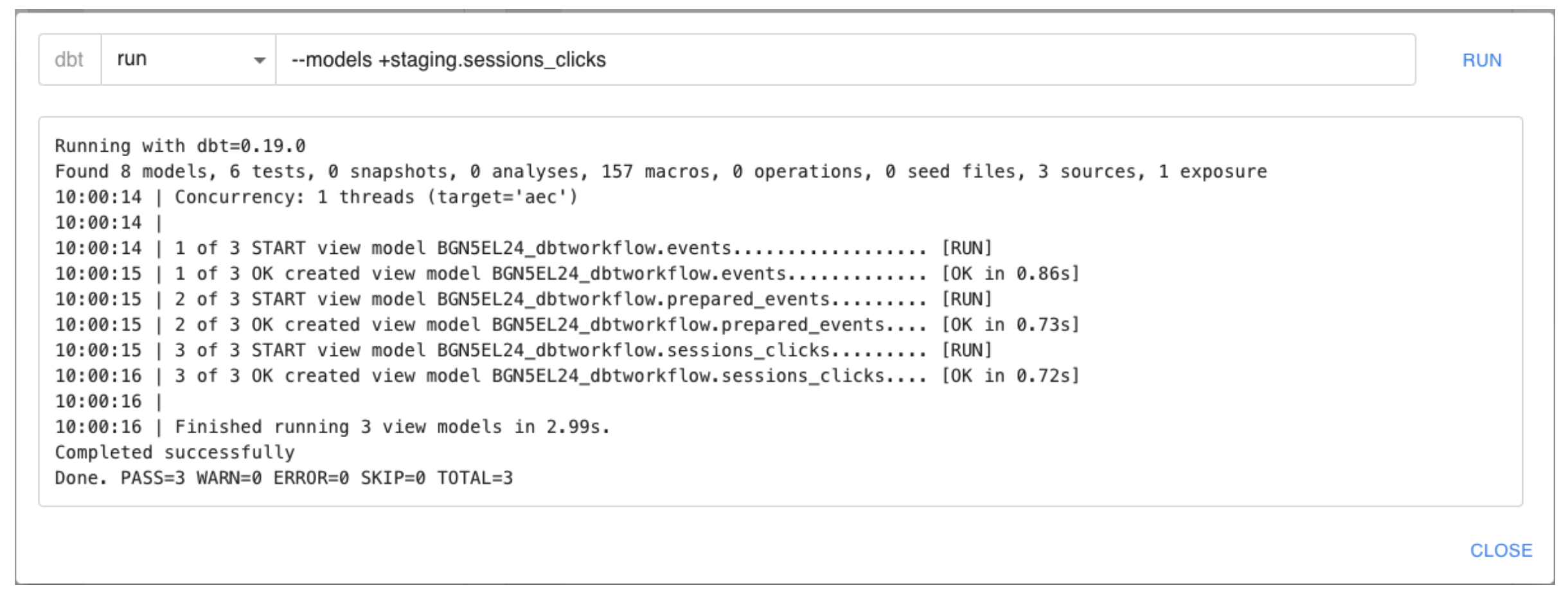
Dans le cas présent, on voit que DBT commence par le modèle events puis prepared_events et enfin sessions_clicks.
Dans cet exemple, tous les modèles sont matérialisés en tant que vues (c’est le comportement par défaut). Cela peut être vérifié dans bigquery pour la vue sessions_clicks par exemple :
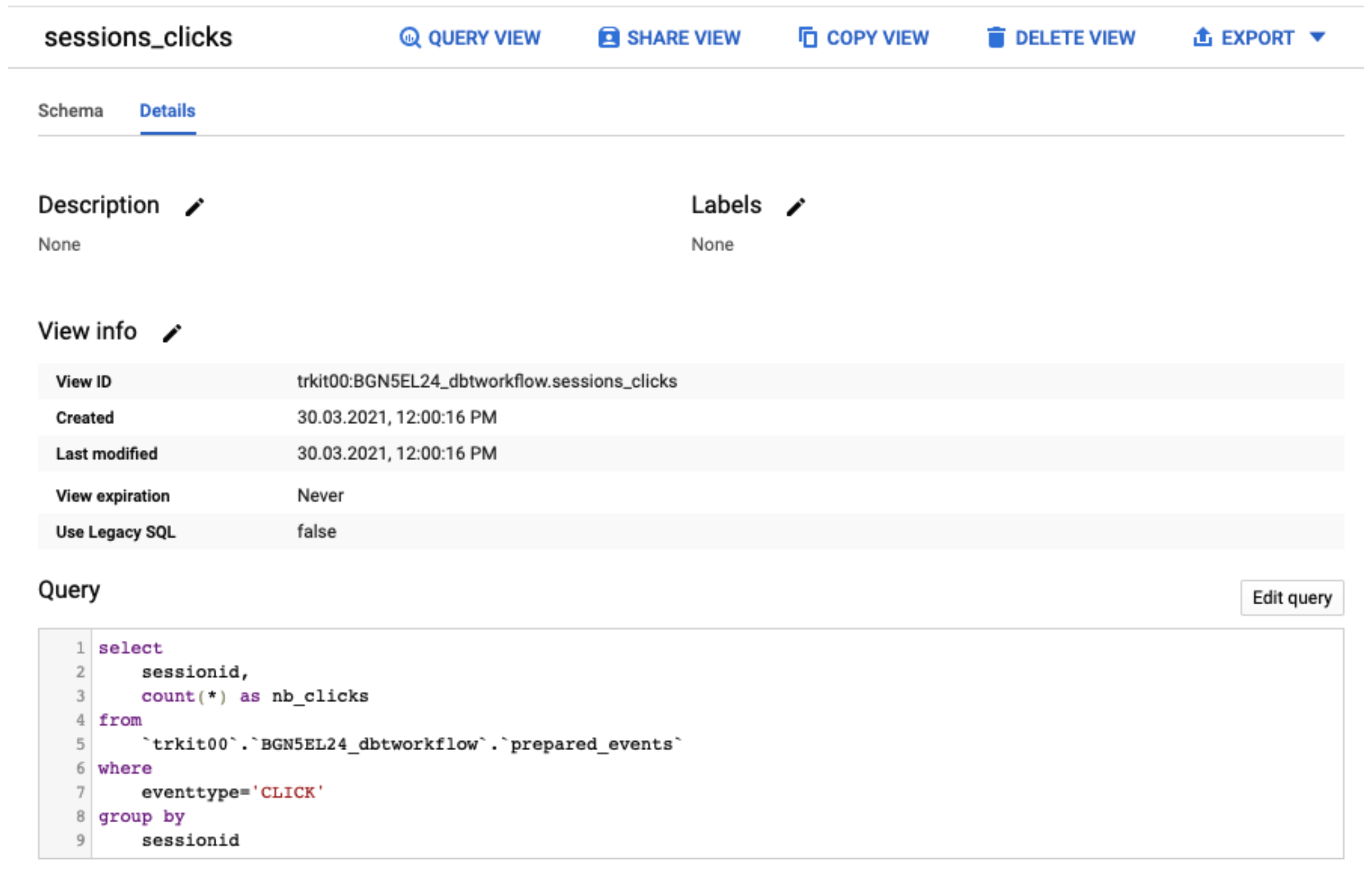
Note : on peut remarquer que DBT a automatiquement remplacé la {{ ref(prepared_events) }} par le nom complet bigquery trkit00.BGN5EL24_dbtworkflow.prepared_events
Conclusion
Dans ce billet, nous avons pu aborder la puissance d’un outil comme DBT pour gérer les transformations au sein du datawarehouse tout en appréciant la simplicité de mise en œuvre à l’aide de la plateforme DataTask.
Dans notre prochaine publication, nous présenterons le workflow de transformation complet mis en place. Cela nous permettra d’approfondir d’autres fonctionnalités des DBT notamment les matérialisations, les options de mise à jour et la gestion de la documentation.
Ce billet fait partie d’une série :
- DataTask pour construire une self-service BI
- Une revue des principaux concepts de dbt et création d’un premier modèle dans DataTask (ce billet)
- L’étude du workflow de transformation complet via DBT ainsi que la présentation de la documentation automatique associée
- Une revue rapide des principales fonctionnalités de Metabase, et plus particulièrement la création d’un dashboard d’analyse automatique, son édition et sa sauvegarde pour publication
- L’utilisation de fonctionnalités supplémentaires de DBT pour améliorer la gouvernance autour de la donnée : la création de tests sur la donnée et documentation de lineage à travers les exposures
- La mise en place d’un pipeline DataTask de manière à assurer la mise à jour automatique des données au cours du temps