
Après avoir étudié l’ensemble du workflow dans les différents billets de la série “self service BI avec Datatask”, je vous propose de détailler les fonctionnalités DataTask qui vont permettre de lancer de manière automatisée ce workflow grace à la création de tâches planifiées mais aussi d’enchainer plusieurs tâches à travers l’utilisation de pipelines.
Les tâches et tâches planifiées dans DataTask
Les tâches permettent de lancer un traitement sur la plateforme. Elles sont définies par :
- Une image docker qui contient le code à exécuter. L’image doit être disponible et accessible dans une registry (dockerhub, Google Container Registry, registry privée…)
- Un fichier de configuration (
manifest.json) qui permet de fixer les différents paramètres à utiliser lors de l’exécution. Ce fichier de configuration est stocké sur le Git dédié à la plateforme.
Dans le cas de traitements DBT, nous avons à disposition une image générique qui permet de récupérer un projet DBT et de lancer l’ensemble des commandes DBT. Il suffira donc d’utiliser cette image dans le fichier manifest.json.
Voici un exemple de fichier manifest.json qui va permettre de lancer la mise à jour du modèle sessions_final et de ses dépendances (voir billets précédents) :
{
"labels": "app:dbtrunsessionsfinal",
"type": "job",
"name": "dbtrunsessionsfinal",
"image-source": "eu.gcr.io/datataskio/dbt-standard:0.1",
"image-destination": "",
"env": [
{
"name": "REPOSITORY",
"value": "aec_trkit_story"
}
],
"cmd": [
"dbt.sh",
"run",
"--models",
"+final.sessions_final",
"--target",
"datatask"
],
"cpu-limit": "0.5",
"memory-limit": "500Mi",
"cpu-request": "0.1",
"memory-request": "100Mi",
"svc-account-secret": "trkit00-metabase"
}
Les paramètres de configuration à noter sont :
type: ici la valeur estjobpour lancer un traitement ponctuel (DataTask peut également déployer des applications ou des APIs par exemple)image-source: l’image DBT standard est utilisée et va permettre de lancer n’importe quelle commande sur nos modèles DBTenv: permet de définir des variables d’environnement utilisées par le code. Ici le nom du repository git qui contient le projet DBT avec l’ensemble des modèlescmd: la commande DBT à lancer. Dans cet exemple il s’agit d’unrunsur le modèlesessions_finalet ses dépendances (et l’utilisation d’un profil de connection à BigQuery nommé “datatask”)
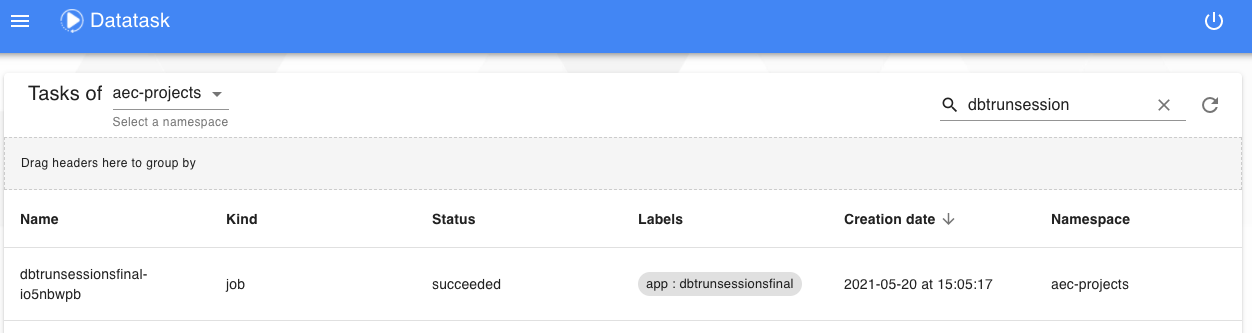
Après le lancement de cette tâche, il est possible de visualiser sont statut :
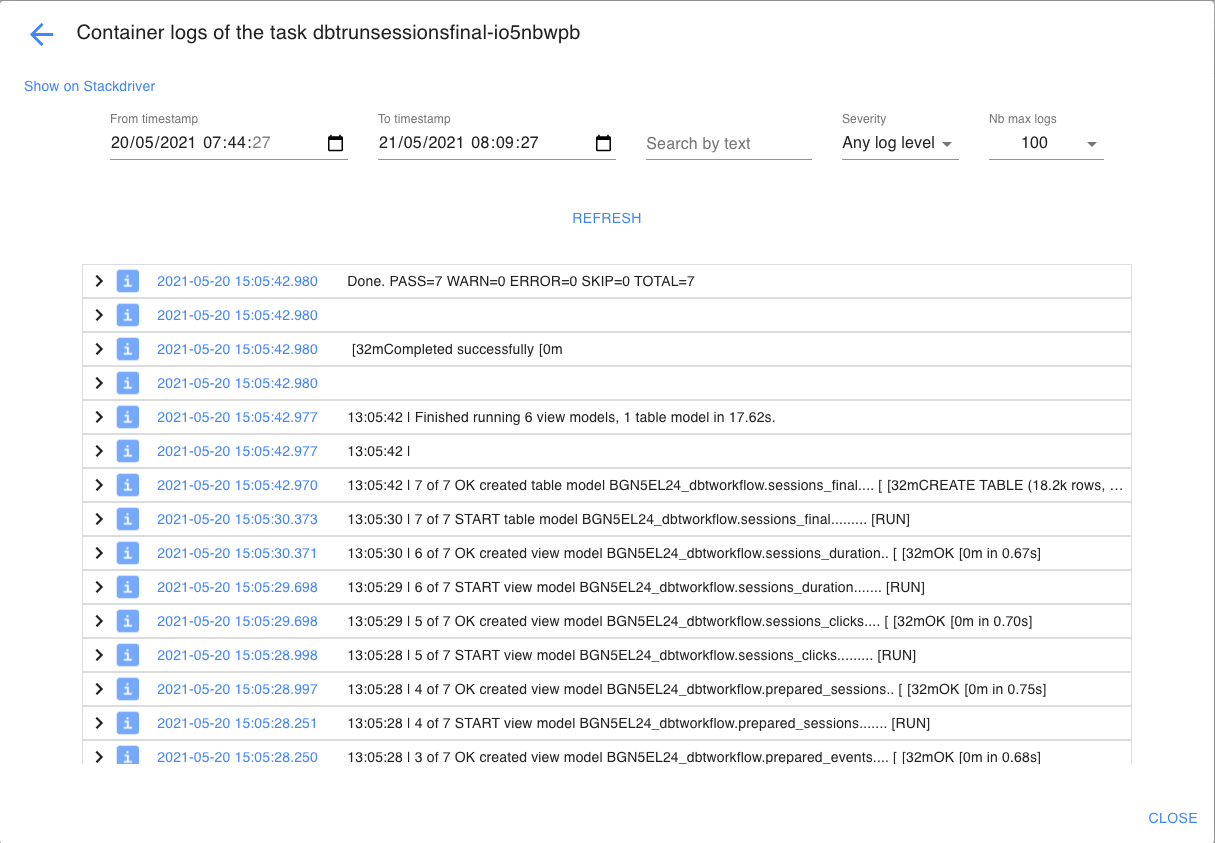
Et de récupérer l’ensemble des logs :
Pour assurer une mise à jour régulière automatique des données, il faut mettre en place une tâche planifiée. Pour cela, il suffit d’ajouter le paramètre schedule avec une syntaxe de type crontab pour préciser la planification.
Par exemple, pour exécuter automatiquement la tâche précédente une fois par jour à 2h du matin on utilisera le manifest.json suivant :
{
"labels": "app:dbtrunsessionsfinal",
"type": "job",
"name": "dbtrunsessionsfinal",
"image-source": "eu.gcr.io/datataskio/dbt-standard:0.1",
"image-destination": "",
"env": [
{
"name": "REPOSITORY",
"value": "aec_trkit_story"
}
],
"cmd": [
"dbt.sh",
"run",
"--models",
"+final.sessions_final",
"--target",
"datatask"
],
"schedule": "0 2 * * *",
"cpu-limit": "0.5",
"memory-limit": "500Mi",
"cpu-request": "0.1",
"memory-request": "100Mi",
"svc-account-secret": "trkit00-metabase"
}
Les pipelines dans DataTask
Dans le paragraphe précédent, nous avons vu comment lancer un traitement DBT de manière ponctuelle ou planifiée mais il peut être intéressant de lancer des workflows qui comprennent plusieurs tâches qui s’enchainent de manière séquentielle ou en parallèle. Dans DataTask, cette fonctionnalité est disponible à travers la configuration d’un pipeline.
Pour renforcer la qualité de données, on va pouvoir définir un pipeline composé :
- d’une première tâche qui réalise des tests sur les données source
- puis une deuxième tâche qui réalisera les transformations définies dans notre modèle uniquement si les tests ne contiennent pas d’erreur.
Comme pour les tâches, un pipeline datatask est défini par un fichier de configuration json (pipeline.json) :
{
"name":"sessionspipeline",
"original":"sessionspipeline",
"tasks":[
{
"name" :"dbttestevents",
"namespacetask":"aec_trkit_story/dbt-test-events"
},
{
"name" :"dbtrunsessions",
"namespacetask":"aec_trkit_story/dbt-run-sessionsfinal",
"dependance": ["dbttestevents"]
}
]
}
Chaque étape du pipeline référence une tâche DataTask (paramètre namespacetask) et chaque tâche peut avoir des dépendances (paramètre dependance).
Dans cet exemple, la première tâche dbttestevents qui réalise les tests n’a pas de dépendance donc elle s’exécutera immédiatement et la seconde tâche dbtrunsessions qui réalise les transformations dépend de dbttestevents elle ne s’exécutera donc qu’après cette dernière et uniquement en cas de succès.
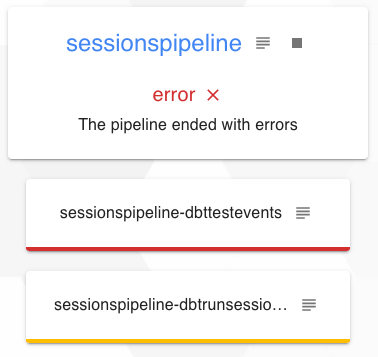
Sur la copie d’écran suivante, on visualise le pipeline après exécution avec la première tâche correspondant aux tests qui est en erreur et la seconde qui n’a donc pas été exécutée.
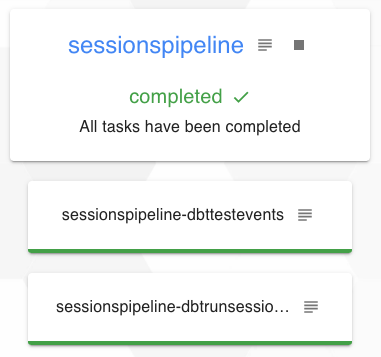
Après avoir corrigé les problèmes sur la data source, en relançant le pipeline, l’exécution peut se dérouler correctement :
Récapitulatif “self service BI sur DataTask”
Les différents billets de cette série nous on permis de mettre en place très facilement un workflow complet de traitement de la donnée avec l’ensemble des fonctionnalités essentielles intégrées à Datatask :
- Un outil de transformation flexible et simple à configurer
- La gestion des dépendances entre les données générées par les transformations
- Une génération automatique de la documentation
- Un outil de visualisation et d’exploration de la donnée générée avec la possibilité de publication de dashboards
- Une amélioration de la gouvernance autour de la donnée grace aux tests et à la documentation du “lineage” pour permettre d’évaluer les risques et les impacts d’une modification par exemple
- L’automatisation des mises jour à travers l’exécution de tâches planifiées ou de pipelines
Ce billet fait partie d’une série :
- DataTask pour construire une self-service BI
- Une revue des principaux concepts de dbt et création d’un premier modèle dans DataTask
- L’étude du workflow de transformation complet via DBT ainsi que la présentation de la documentation automatique associée
- Une revue rapide des principales fonctionnalités de Metabase, et plus particulièrement la création d’un dashboard d’analyse automatique, son édition et sa sauvegarde pour publication
- L’utilisation de fonctionnalités supplémentaires de DBT pour améliorer la gouvernance autour de la donnée : la création de tests sur la donnée et documentation de lineage à travers les exposures
- La mise en place d’un pipeline DataTask de manière à assurer la mise à jour automatique des données au cours du temps (ce billet)