
Dans un précédent blog, nous avons exploré comment DuckDB permet d’effectuer des transformations SQL directement sur les données stockées dans un Datalake, sans nécessiter leur chargement préalable dans une base de données. Cette méthode allège considérablement les contraintes architecturales liées aux données et facilite le flux d’informations. Toutefois, la pratique d’insérer des commandes SQL dans un script Python et de les orchestrer peut sembler désuète après avoir expérimenté la simplicité de modélisation sémantique offerte par DBT. Examinons donc comment tirer parti, au sein de DataTask, des avantages combinés de ces deux outils.
DBT se distingue par sa modularité, séparant l’expression de la modélisation SQL de son exécution, et ce, en s’appuyant sur une large gamme de moteurs. DuckDB est l’un de ces moteurs et propose nativement des options pour configurer dans le profil utilisateur les accès au datalake, où seront stockés les fichiers. (ex: profile.yaml).
Sources
Avec DBT, il devient possible de diriger les sources vers divers fichiers parquet (entre autres formats), en utilisant une syntaxe qui précise comment les tables doivent être matérialisées. Une métadonnée ’external_location’ est spécifiée, indiquant l’emplacement où l’attribut ’name’ des tables définies sera injecté. Les tables sont alors accessibles dans les scripts SQL sous ce nom spécifié. La fonctionnalité ’*’ permet d’agréger tous les fichiers parquet situés dans ’external_location’ en une table unique, à condition que tous les fichiers partagent un format identique. La dernière option, ‘allwithfilename’ introduit dans la table générée une colonne ‘filename’, qui contient le nom de chaque fichier.
sources:
- name: crypto
meta:
external_location: "s3://crypto-histo/crypto/parquet/{name}.parquet"
tables:
- name: YFIEUR
- name: ZRXBTC
- name: "*"
- name: "allwithfilename"
meta:
external_location: "read_parquet('s3://crypto-histo/crypto/parquet/*.parquet',filename=True)"
Modélisation
L’intégration d’une table, telle que décrite précédemment, pour élaborer un modèle DBT au sein de DataTask se révèle être une démarche plutôt aisée :
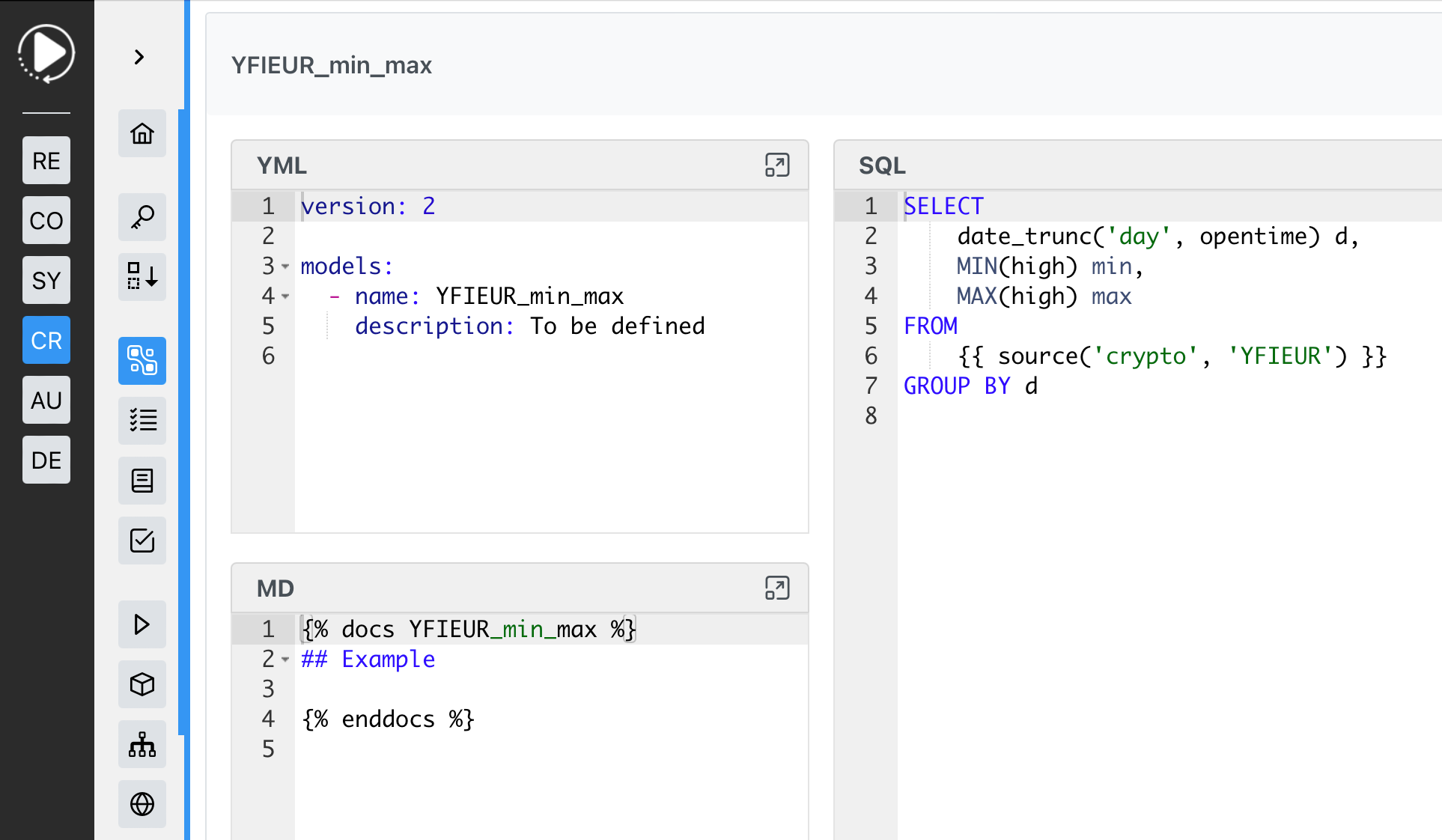
DBT génère des vues par défaut. Cependant, si l’on préfère matérialiser les données en fichiers parquet, il suffit d’ajouter un petit bloc de configuration au modèle :
{{
config(
materialized='external',
location='s3://crypto-histo/crypto/dbt-test/YFIEUR_min_max.parquet'
)
}}
L’avantage principal de l’élaboration de ces transformations SQL avec DBT réside dans la capacité à obtenir une documentation complète ainsi que le lignage des modèles.
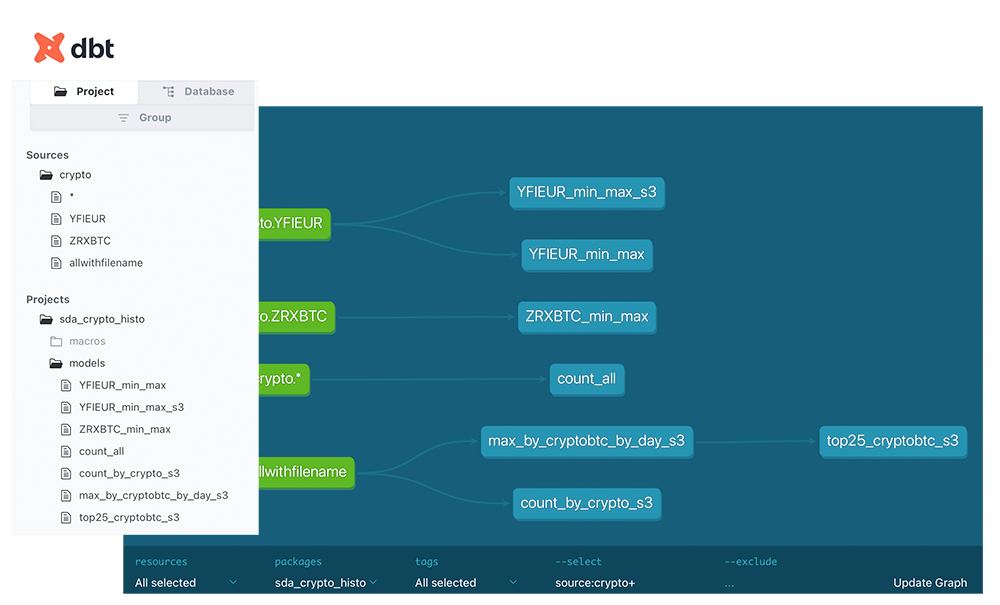
Passer en production
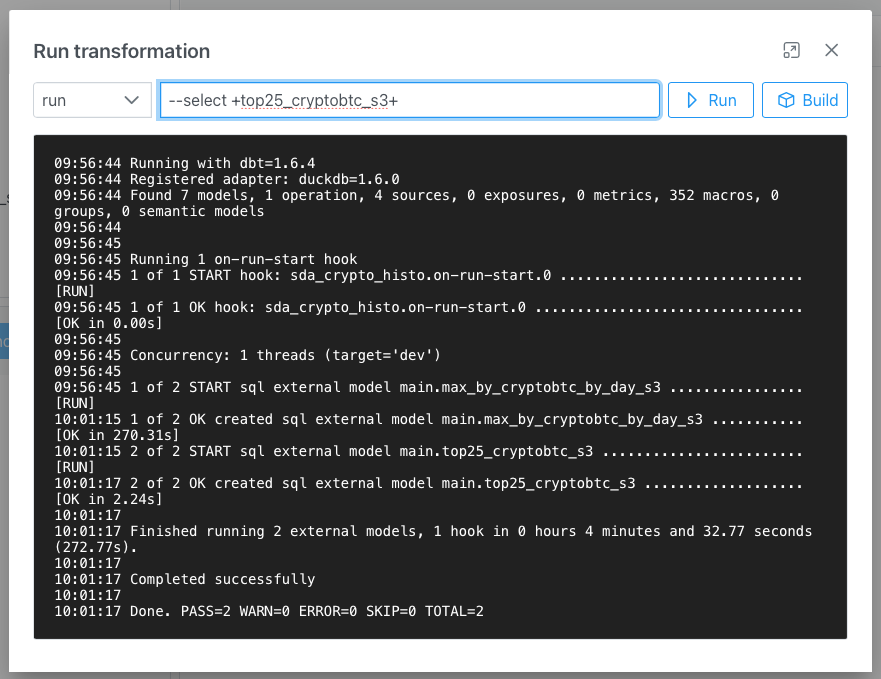
Depuis le module Transform, il est possible de déclencher l’exécution de l’ensemble des modèles DBT présents dans le projet, ou d’utiliser un sélecteur pour, par exemple, exécuter un modèle spécifique avec ses dépendances. Après avoir effectué un test, cette interface offre l’option de créer un artefact, qui permet de conserver les paramètres d’exécution dans une tâche réutilisable. Une fois cet artefact créé, il suffit de le programmer ou de l’intégrer dans un ensemble d’opérations pour automatiser son exécution en production !
Une fois de plus, la puissance de DataTask ouvre la voie à des scénarios innovants pour valoriser vos données, s’écartant des approches conventionnelles. L’utilisation directe des données stockées sur le Datalake favorise une accélération de votre stratégie de Data Warehousing sans nécessiter l’investissement dans une coûteuse base de données OLAP.