
La donnée est devenue un élément structurant de la transformation des entreprises quelles que soient leurs tailles, et leurs domaines d’activités. La capacité à faire de la donnée un actif utilisé et utilisable par tous dans l’organisation est un élément clé et permet de générer un niveau d’engagement très élevé. Cette démocratisation requiert de rendre la donnée disponible et de faire que l’outillage autour des processus soit aussi performant qu’abordable.
La mise en place d’un workflow automatisé et scalable assurant le chargement, le traitement et la mise à disposition de la donnée raffinée n’est pas toujours aisée et rapide. Dans cette série de blogs, nous allons voir comment notre plateforme DataTask permet de définir et gérer les différentes étapes d’un workflow sans nécessiter d’expertise avancée dans les architectures data.
Ce premier billet va permettre de présenter le workflow global mis en place ainsi que l’architecture et les différents outils utilisés. Les billets suivants seront dédiés à une étude plus approfondie de chacune des étapes de mise en œuvre.
Workflow
Dans notre cas, nous allons récupérer de la donnée web analytics (les pages visitées et clics sur les sites d’affini-tech), créer de nouveaux indicateurs à partir de cette donnée source et exposer cette nouvelle donnée dans un outil de visualisation pour analyser le comportement des utilisateurs.
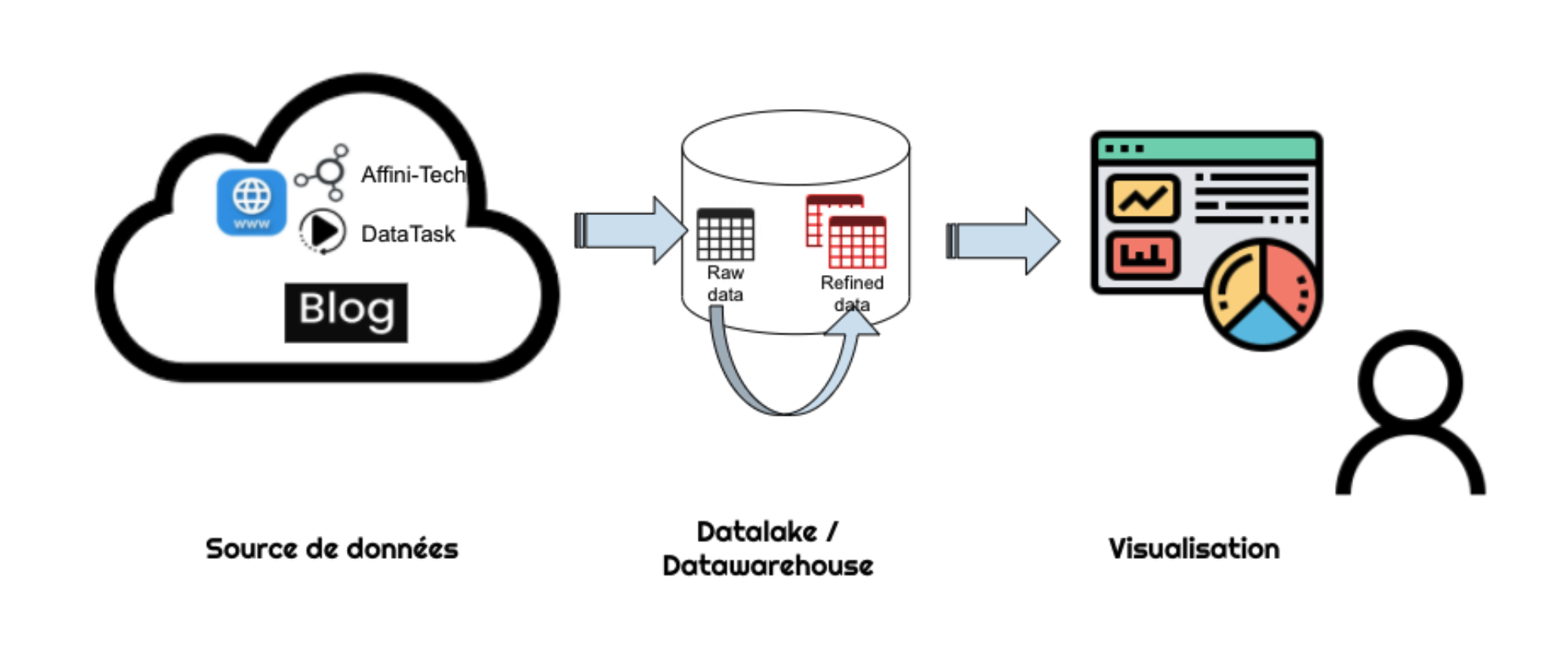
Architecture
Datatask permet d’opérer le workflow complet et d’offrir des briques simples pour le construire. Basé sur des “moteurs” open-source, Datatask offre une interface qui permet de configurer et de piloter les traitements.
Dans notre cas la source de donnée est déjà présente dans le Datawarehouse, puisqu’il s’agit de données de tracking d’audience récupérées par notre outil trkit. Google BigQuery, le datawarehouse managé hautement scalable de Google, est un choix cohérent pour délivrer une performance importante avec une grande facilité d’opération.
Datatask permet d’organiser les flux et d’assurer les transformations de données, ainsi que la présentation de celles-ci. Cette intégration de bout en bout s’appuie sur des projets open-source comme DBT pour la transformation des données, et sur Metabase pour assurer la présentation et le partage. DBT permet de construire des transformations SQL des données pour modéliser les règles business. Il les rend accessibles. Metabase permet d’exposer la donnée dans des dashboards explicites, mais aussi de permettre à des utilisateurs métier de s’approprier la donnée pour répondre à des questions.
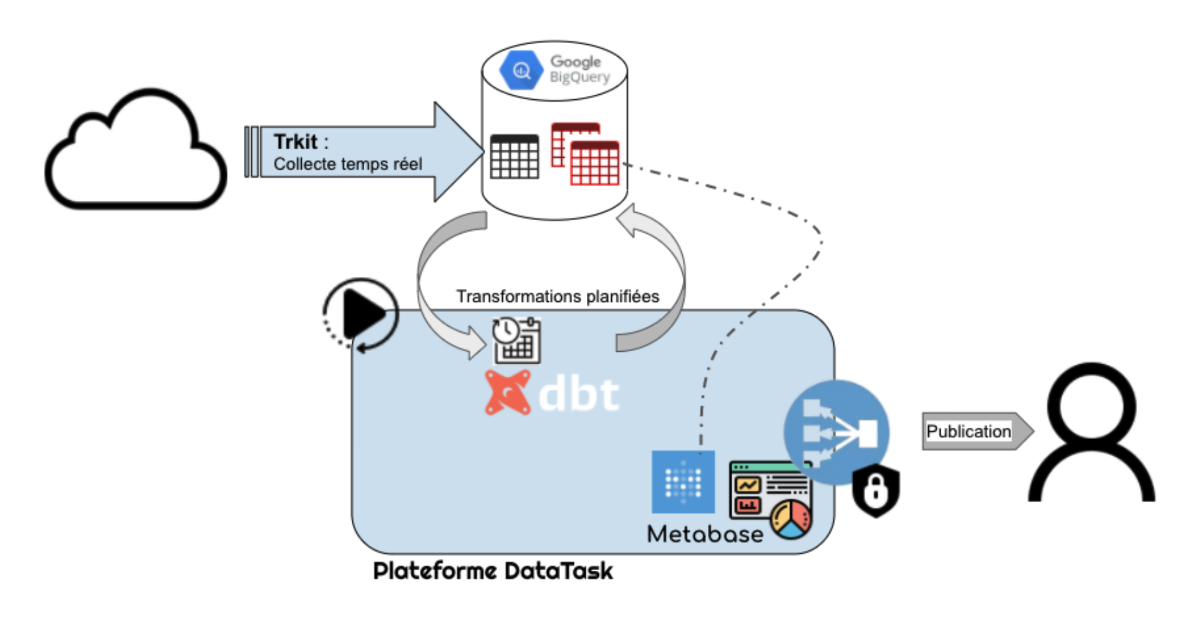
Transformation des données
En quelques lignes de code SQL dans la “Smart Data Analytics” on parvient à coder les transformations et à documenter le processus. Il peut s’agir d’aggrégation, d’enrichissement, tout comme l’application de rêgles métier sur les données. Un prochain billet nous permetttra d’approfondir cette phase de transformation des données.
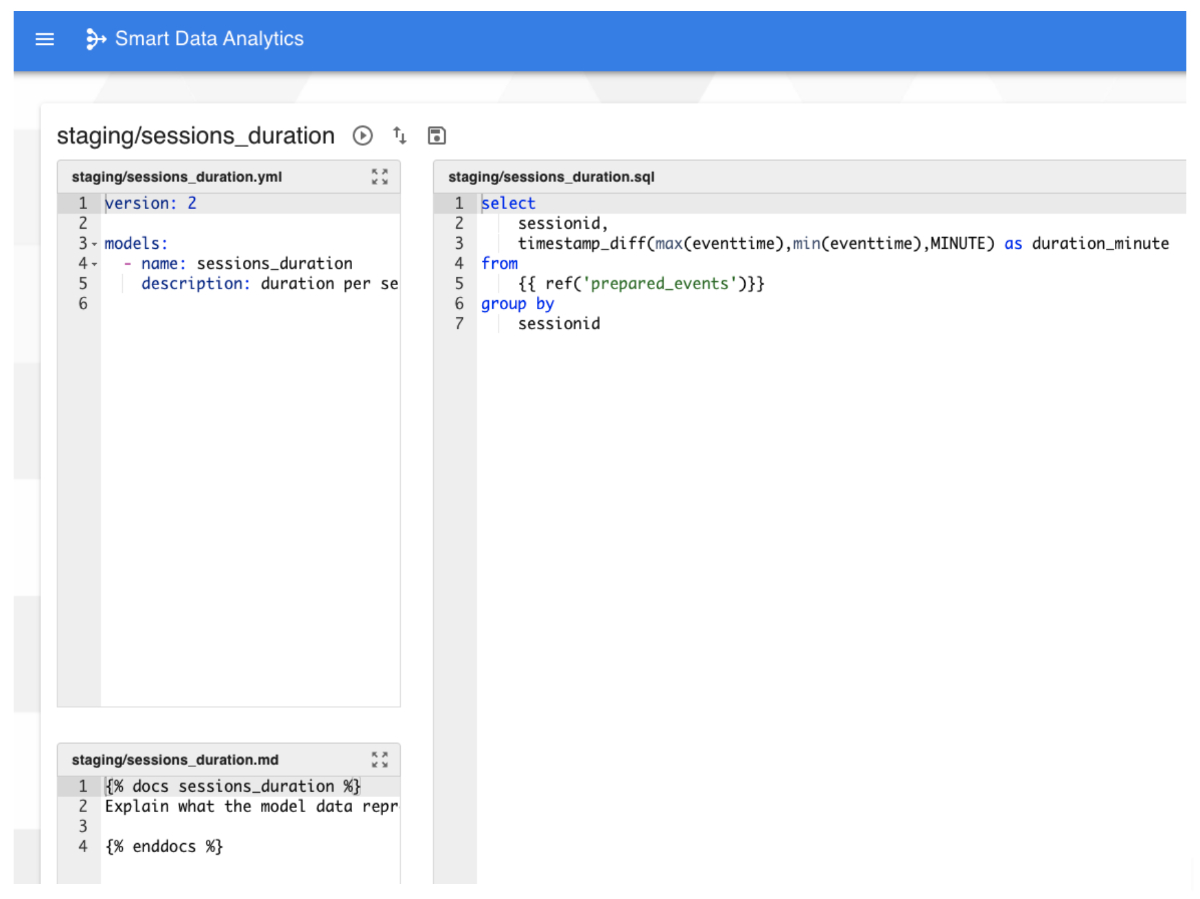
Self Service BI
Un dashboard peut alors être créé pour donner un aperçu rapide des différentes métriques liées au trafic sur les sites à analyser. Ce dashboard peut être produit quasi automatiquement sans intervnetion de l’utilisateur, comme il peut être ajusté pour répondre à des besoins très précis. Le dashboard est rendu accessible aux utilisateurs à travers la plateforme DataTask :
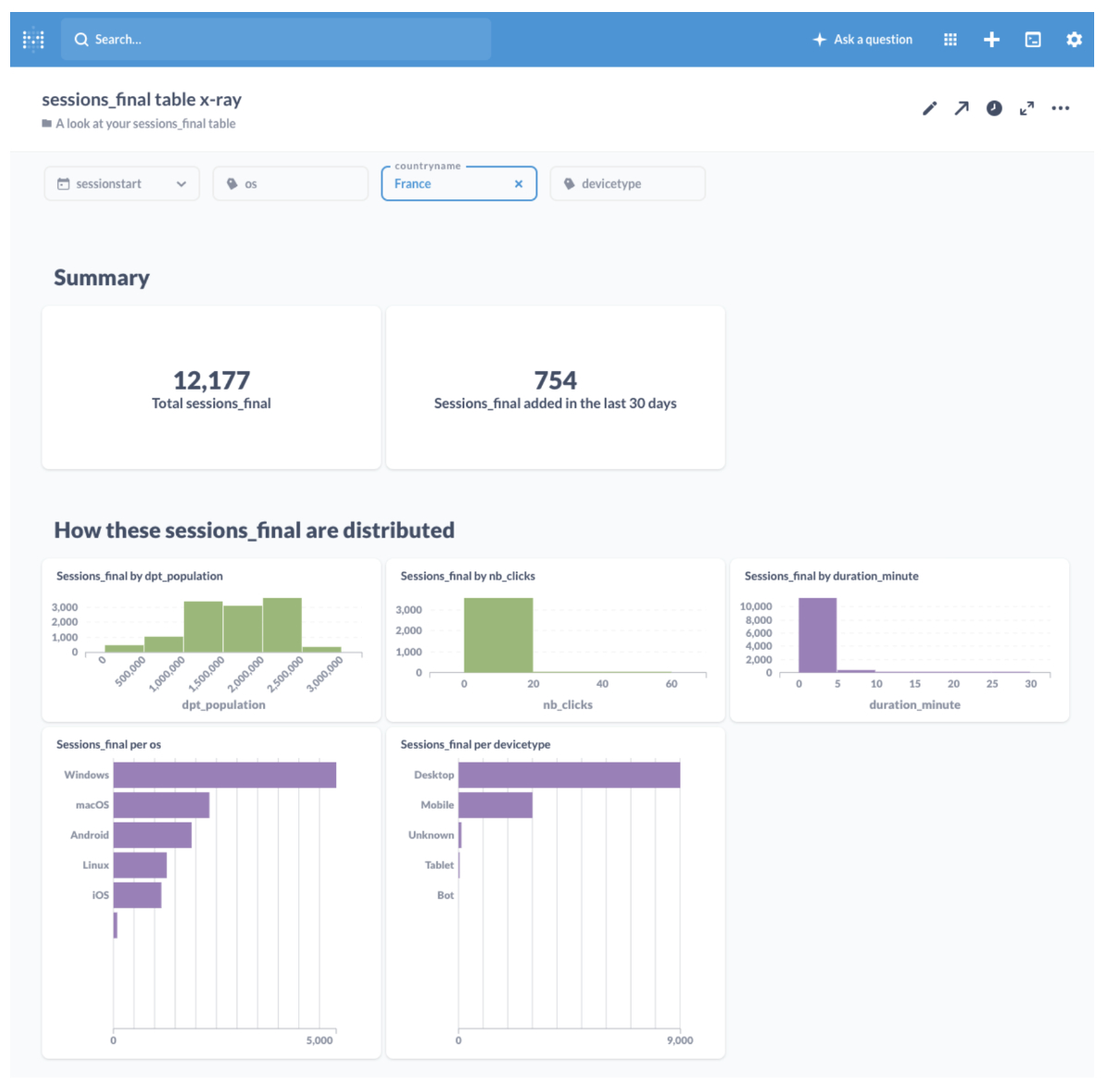
Pour aller plus loin
Ce billet vous donne un aperçu de la simplicité avec laquelle les données peuvent être utilisées dans DataTask, pour être transformées et exposées dans une BI. Lors de nos prochains billets nous vous présenterons chaque étape du workflow plus en détail.
- DataTask pour construire une self-service BI
- Une revue des principaux concepts de dbt et création d’un premier modèle dans DataTask (ce billet)
- L’étude du workflow de transformation complet via DBT ainsi que la présentation de la documentation automatique associée
- Une revue rapide des principales fonctionnalités de Metabase, et plus particulièrement la création d’un dashboard d’analyse automatique, son édition et sa sauvegarde pour publication
- L’utilisation de fonctionnalités supplémentaires de DBT pour améliorer la gouvernance autour de la donnée : la création de tests sur la donnée et documentation de lineage à travers les exposures
- La mise en place d’un pipeline DataTask de manière à assurer la mise à jour automatique des données au cours du temps