
Après un exercice personnel d’exploration des données comptables avec les outils de séries temporelles, Je me suis demandé si je pouvais faire la même chose avec la Smart Data Analytics (SDA) de DataTask.
Les données comptables en France sont disponibles au format “FEC”, Fichiers d’Ecritures Comptables. Sa spécification est disponible sur le site du BOFIP. Ce qu’il vous faut savoir :
- Il s’agit d’un fichier au format CSV avec la tabulation utilisée comme séparateur de champ,
- Chaque ligne du fichier correspond à une opération comptable ; on y retrouve donc des informations de date, de nature (débit/crédit), le compte associée à l’opération, un intitulé d’opération, etc.
- Ce fichier peut être utilisé dans le cadre d’audit/contrôle par l’administration.
Dans le cadre de ce cas d’usage nous allons :
- Ingérer les fichiers (1 par année) déposés sur un bucket Google Storage,
- Importer les données dans un dataset sur BigQuery
- Appliquer un algorythme de prévision avec BigQuery ML
- Explorer les données et créer des dashboards pour le compte de trésorerie et le compte de résultat.
Préparation du projet
Pour la partie BigQuery ML, il est nécessaire d’installer le plugin dbt_ml pour que DBT soit en mesure de manipuler les modèles de machine learning.
Dans votre projet Smart Data Analytics, il faut ajouter le fichier packages.yml contenant:
packages:
- package: kristeligt-dagblad/dbt_ml
version: 0.5.0
et il faut modifier le fichier dbt_project.yml pour y ajouter deux blocs de contenus :
# bqml related variables & on-run-start blocks
vars:
"dbt_ml:audit_schema": "audit"
"dbt_ml:audit_table": "ml_models"
on-run-start:
- '{% do adapter.create_schema(api.Relation.create(target.project, "audit")) %}'
- "{{ dbt_ml.create_model_audit_table() }}"
[...]
models:
aec_fec:
materialized: view
source:
materialized: table
# bqml related configuration
ml:
enabled: true
schema: ml
materialized: model
post-hook: "{{ dbt_ml.model_audit() }}"
L’explication de ces paramètres sort du cadre de l’objet de ce billet. Il faudra consuler la documentation de DBT et/ou du plugin pour en savoir plus.
Votre projet est alors configuré. Nous pouvons passer à la configuration des connections.
Définition de la connection
Nos données étant dans un bucket sur Google Object Storage et devant terminer dans Google BigQuery, nous devons déclarer une connection se basant sur un compte de service Google. Cette connection permettra ensuite de se connecter au bucket et/ou à BigQuery.
Dans votre projet, cliquer sur Connections dans le menu de gauche :
Puis sur New dans la zone centrale et choisir Google Service Account
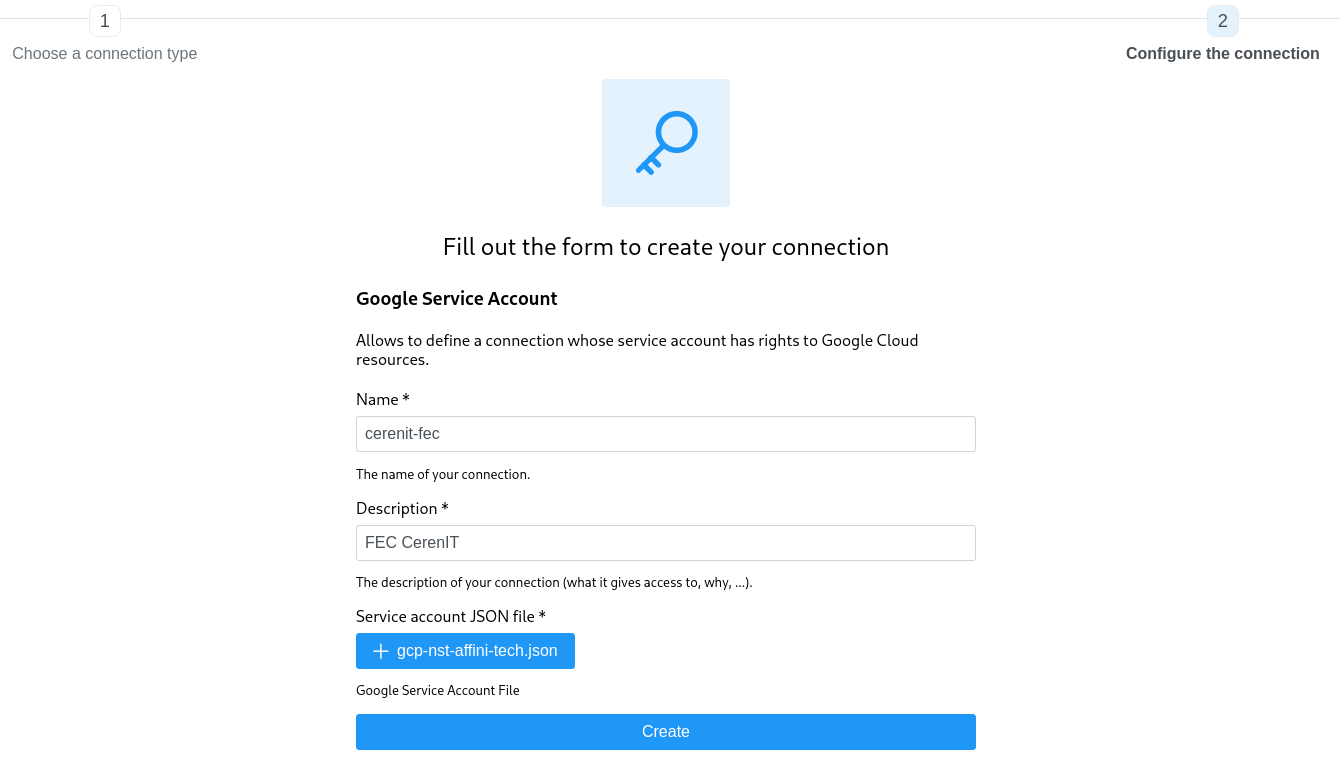
Indiquer un nom (caractères alphanumériques et tiret autorisés), une description et sélectionner le fichier de compte de service disposant des droits suffisant pour interagir avec Google Storage et Google BigQuery. Une fois rempli, cliquer sur Create.
Votre connection est alors créée:
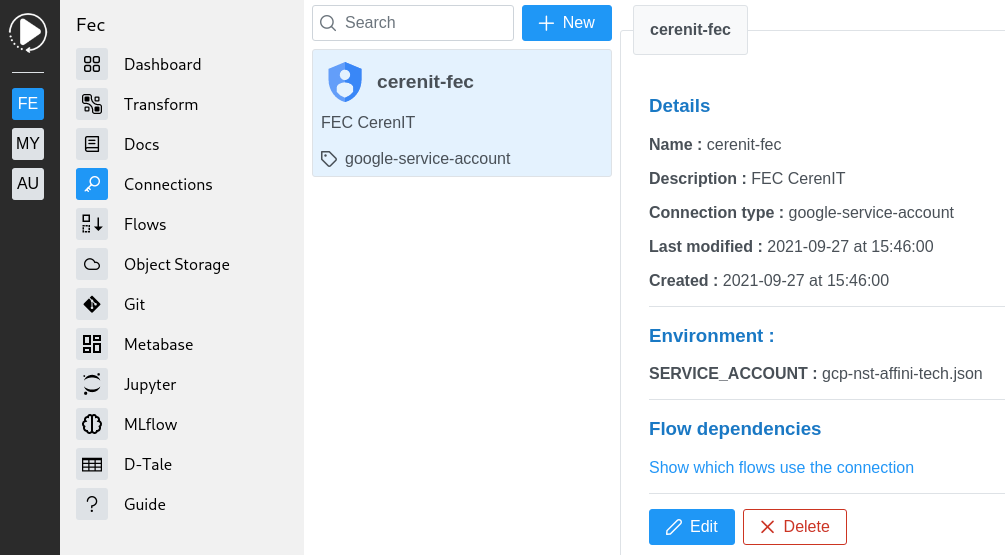
C’est tout ce dont nous avons besoin pour notre cas d’usage. Passons au Flow.
Définition du Flow
Nous allons décrire un flow qui va lire les fichiers FEC depuis Google Storage et envoyer les données dans Google BigQuery. Dans notre flow, nous allons donc choisir un reader de type CSV et une writer de type BigQuery
Dans votre projet, cliquer sur Connections dans le menu de gauche puis sur New. Sélectionner la connection que nous venons de définir puis choisir le CSV Reader dans la liste des readers :

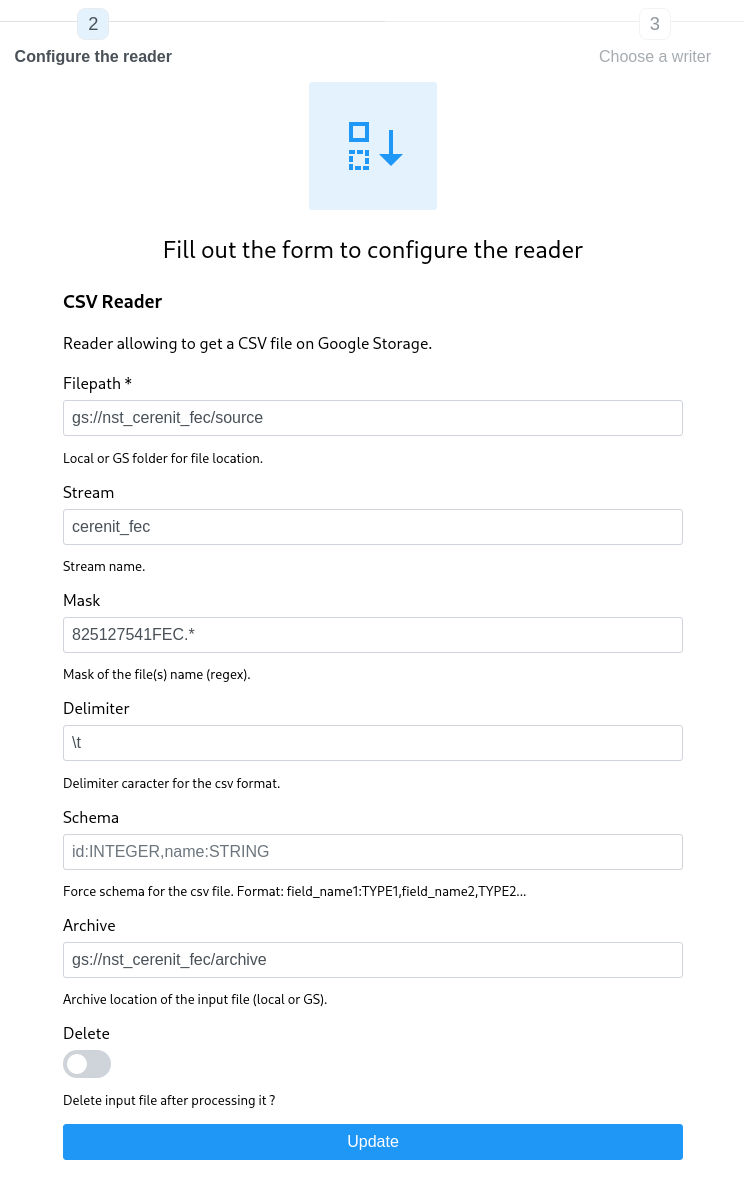
Remplir les informations demandées :
- pour Google Storage, il faut absolument que les fichiers ne soient pas à la racine du bucket
- personnaliser le nom du stream à votre convenance
- le masque permet d’utiliser des expressions régulières pour identifier un à plusieurs fichiers dans une liste de fichiers ; nos fichiers sont de la forme
<SIRET>FEC<YYYYMMDD>.txt, nous retenons donc825127541FEC.*comme masque pour tous les englober - dans le cas présent, nous n’avons pas besoin de personnaliser/forcer le schema
- le bucket d’archive est le bucket où seront déposés les fichiers post traitement
- delete indique s’il faut supprimer ou pas les fichiers dans le dossier source.
Le reader est créé, passons au writer ; il faut choisir la connexion que nous avons défini et BigQuery.
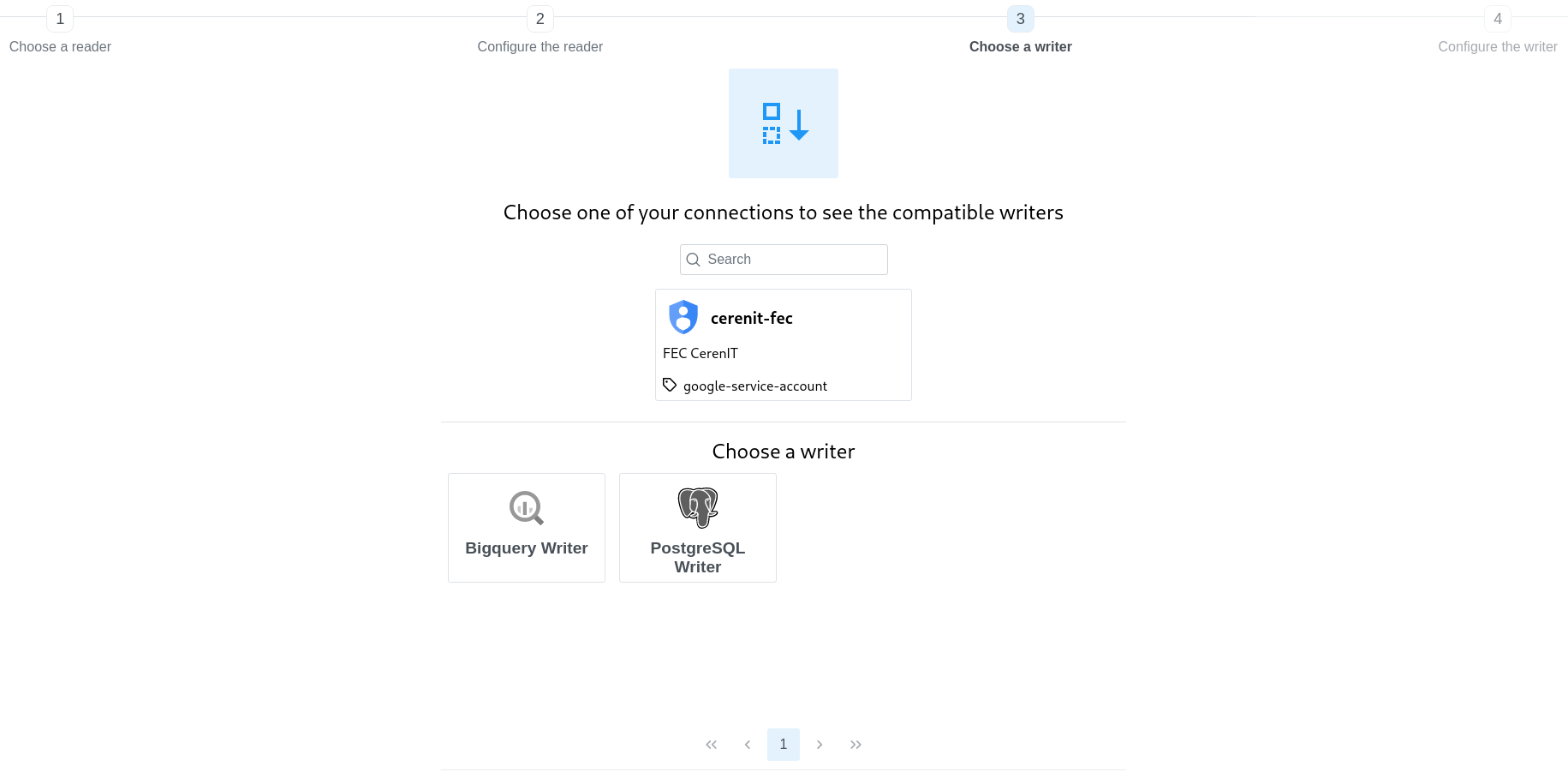
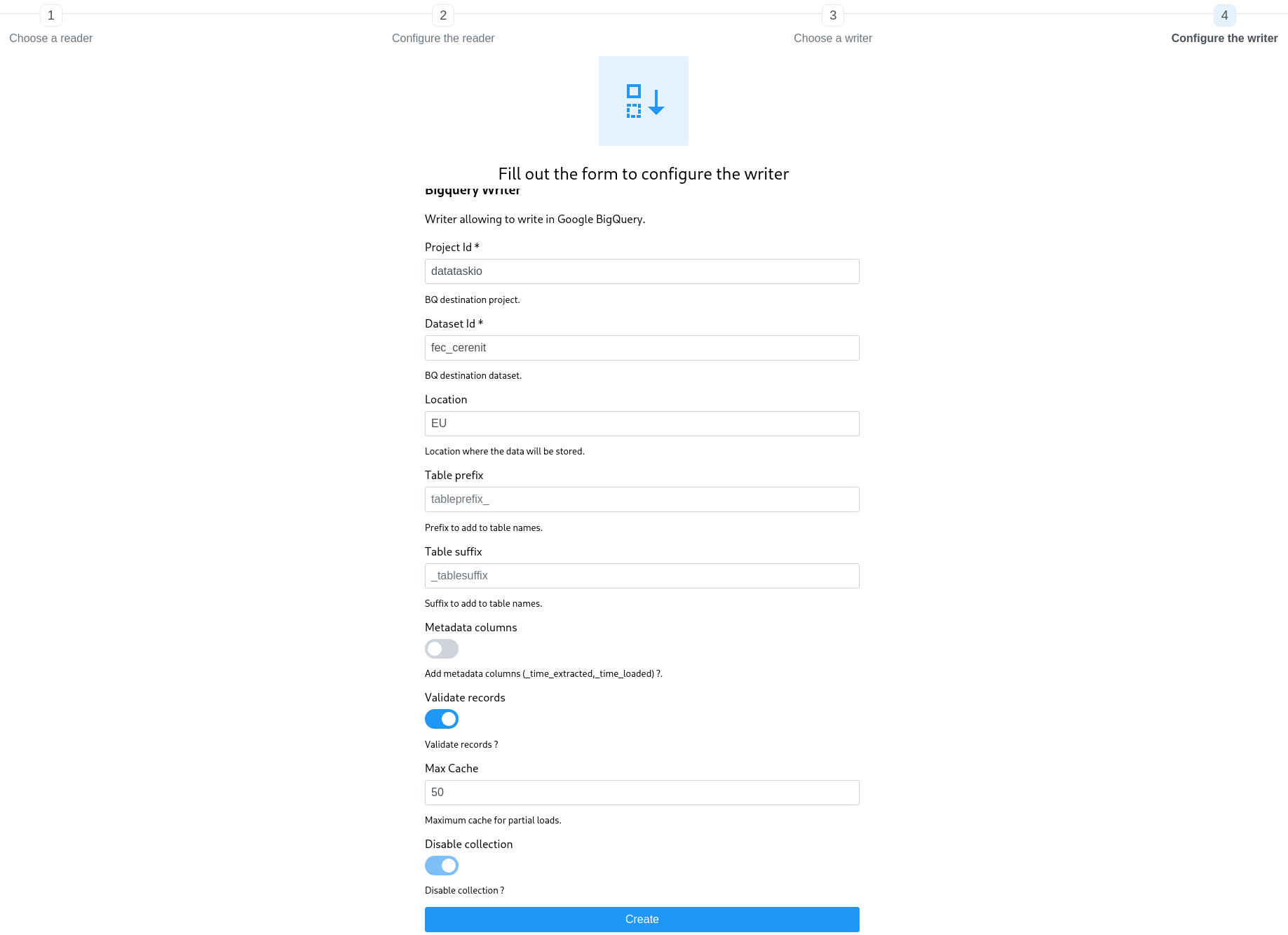
Remplir les valeurs demandées pour BigQuery puis cliquer sur Create
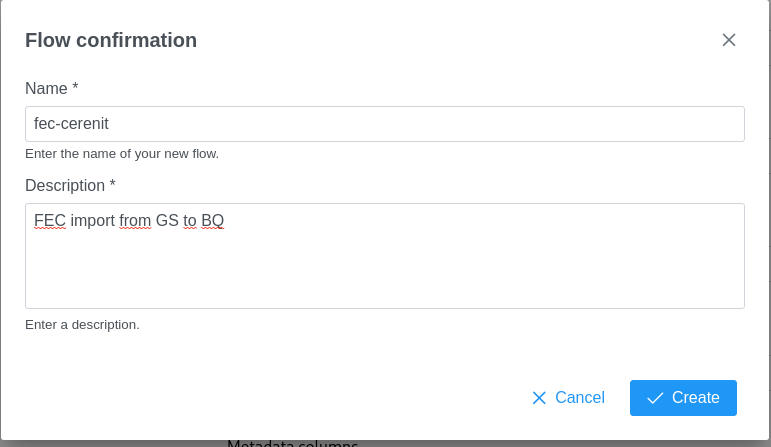
Une fenêtre modale vous demande alors de donner un nom et une description à votre flow. Une fois remplis, cliquer sur Create.
Le flow est créé :

Exécution du flow
En cliquant sur le flow, nous arrivons sur un écran depuis lequel on peut éditer le flow, le supprimer mais ce qui nous intéresse c’est de pouvoir l’exécuter pour valider son fonctionnement. En cliquant sur Launch, nous lançons l’exécution de notre flow. Il a alors un statut “active”.

Une fois exécuté, le status est mis à jour (succeeded ou failed) et la date de fin du traitement est indiquée :

Si nous nous rendons dans BigQuery, nous retrouvons notre dataset et notre table :
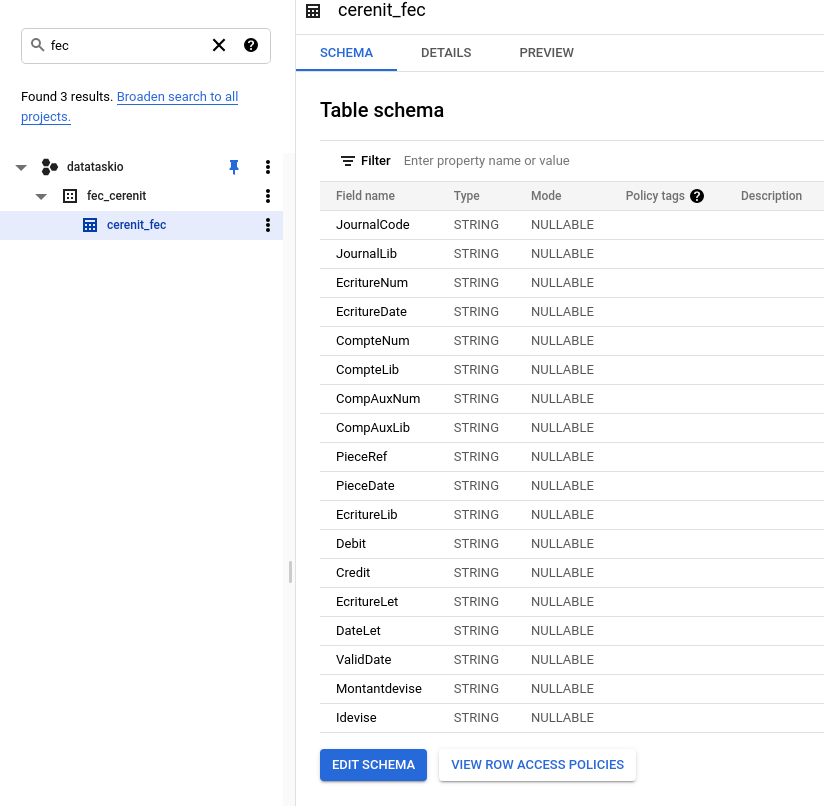
A ce stade, nous avons donc complètement automatisé l’ingestion des fichiers FEC depuis un bucket Google Storage vers un dataset BigQuery
Source
Pour que DBT puisse manipuler nos données, il nous faut lui indiquer où est la source de données.
En cliquant sur Transform, la partie du bas permet de déclarer des sources. Puis sur New, Saisir un nom (dans notre cas “fec”) et cliquer sur Create. La liste des sources est alors actualisée.
Cliquer sur la source puis sur Show - nous avons alors accès à l’ensemble des propriétés d’une source DBT.
Dans le cadre de cet exemple, nous allons prendre une déclaration minimaliste :
- nous indiquons le dataset et la table contenant les données
- nous précisons qui en est à l’origine avec la prioriété
loader - nous indiquons un nom à la source et une description à la table
version: 2
sources:
- name: fec_cerenit
dataset: fec_cerenit
loader: singer
tables:
- name: cerenit_fec
description: "FEC Data for CerenIT"
Cliquer sur Save une fois la source saisie.
Première transformation : les comptes de bilan
Notre première transformation va consister à rassembler toutes les écritures des classes de compte du bilan, à savoir les classes 1 à 5. Nous en profitons également pour transformer des champs de type STRING (chaine de caractères) vers des champs de type DATE et aussi changer le format des opérations de débit/crédit pour être vu comme des nombres et avoir le bon séparateur pour les centimes.
En cliquant sur Transform puis sur New, nous allons créer un modèle pour notre bilan dans un sous-dossier fec. Une fois le nom saisi, cliquer sur Create.
L’explorateur de modèles est alors mis à jour et nous pouvons sélectionner le modèle et cliquer sur Show pour accéder à son contenu.
Par défaut, nous avons toutes les options d’un modèle. Comme pour la source, nous allons nous limiter à l’essentiel :
En commençant en haut à gauche, nous allons avoir le bloc de déclaration du modèle. Nous donnons simplement un nom et une description.
#fec/bilan.yml
version: 2
models:
- name: "bilan"
description: "create bilan table from account class 1 to 5"
docs:
show: true
En dessous, nous donnons un minimum de documentation que nous pourrons uitliser ultérieurement :
# fec/bilan.md
{% docs bilan %}
Create a bilan table based on account class (1 to 5), cast debit/credit as numeric values, cast date fields as date
{% enddocs %}
Enfin, nous déclarons les traitements que nous allons apporter sur nos données :
- La configuration permet d’indiquer le type de rendu que nous voulons, ici une table
- la parttie select comprend la requête que nous allons faire pour récupérer l’ensemble des éléments, faire les transformations de format indiquées précédemment, la source de données avec les valeurs définies sur la source et enfin la restriction sur les classes de comptes de 1 à 5
{{
config(
materialized='table',
)
}}
select
JournalCode,
JournalLib,
EcritureNum,
EcritureDate,
CompteNum,
CompteLib,
CompAuxNum,
CompAuxLib,
PieceRef,
DATE(Parse_datetime("%Y%m%d",PieceDate)) as PieceDate,
EcritureLib,
cast(REPLACE (Debit, ",", ".") as numeric) as Debit,
cast(REPLACE (Credit, ",", ".") as numeric) as Credit,
EcritureLet,
IF(DateLet="", NULL, DATE(Parse_datetime("%Y%m%d",DateLet))) as DateLet,
DATE(Parse_datetime("%Y%m%d",ValidDate)) as ValidDate,
Montantdevise,
Idevise
from {{source('fec_cerenit', 'cerenit_fec')}}
WHERE LEFT(CompteNum,1) IN ("1","2","3","4","5")
On peut alors cliquer sur Save puis sur Run pour exécuter notre transformation. Une fenêtre s’ouvre avec des valeurs prépositionnées pour notre exécution. Cliquer sur Run pour voir le résultat
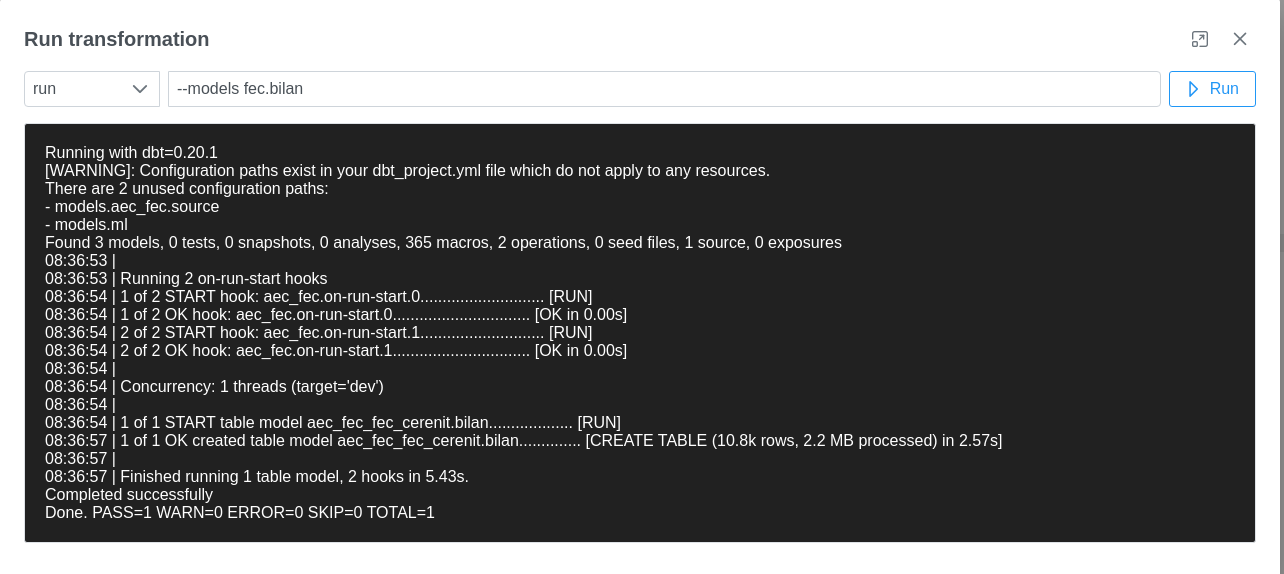
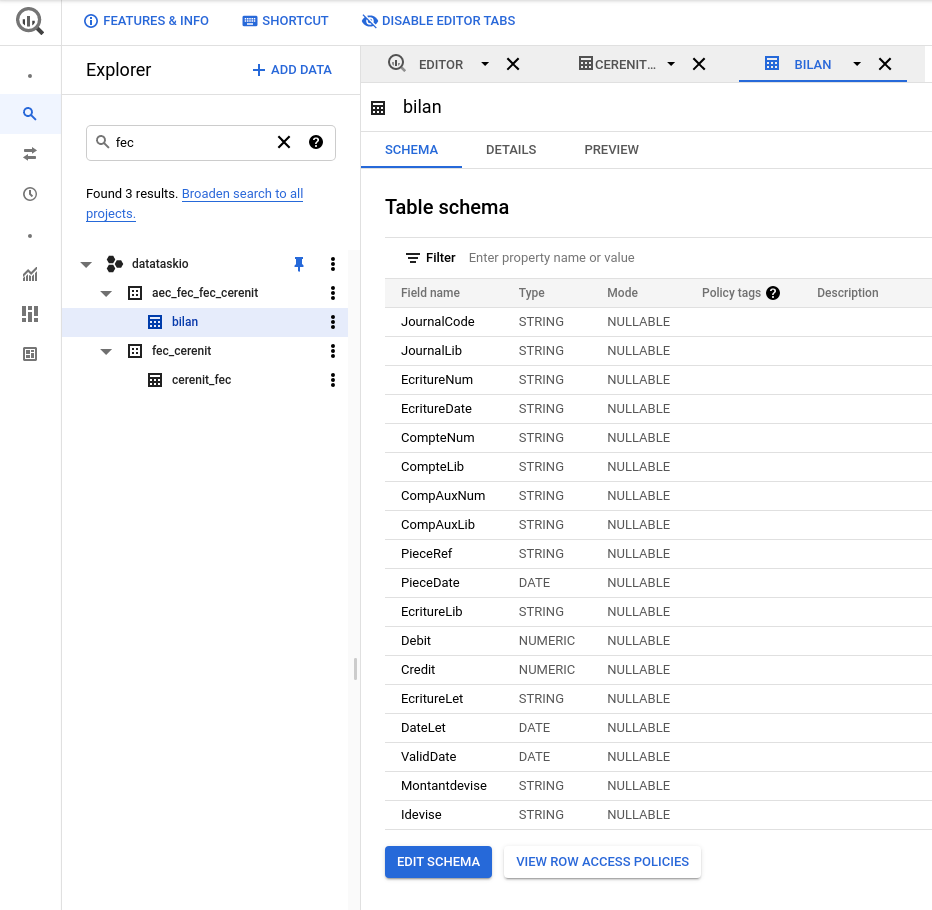
Nous pouvons alors nous rendre dans BigQuery pour valider que les données sont bien disponibles :
Seconde transformation : les comptes de résultat
Sur le même modèle, nous allons créer un modèle fec/resultat en prenant cette-fois ci les classes de compte 6 et 7 :
version: 2
models:
- name: resultat
description: Create resultat table from 6 & 7 class accounts
docs:
show: true
#fec/resultat.md
{% docs resultat %}
Create resultat table from 6 & 7 class accounts, cast debit/credit as numbers, cast date fields as date
{% enddocs %}
et la même transformation mais appliquée aux classes de comptes 6 et 7 :
{{
config(
materialized='table',
)
}}
select
JournalCode,
JournalLib,
EcritureNum,
EcritureDate,
CompteNum,
CompteLib,
CompAuxNum,
CompAuxLib,
PieceRef,
DATE(Parse_datetime("%Y%m%d",PieceDate)) as PieceDate,
EcritureLib,
cast(REPLACE (Debit, ",", ".") as numeric) as Debit,
cast(REPLACE (Credit, ",", ".") as numeric) as Credit,
EcritureLet,
IF(DateLet="", NULL, DATE(Parse_datetime("%Y%m%d",DateLet))) as DateLet,
DATE(Parse_datetime("%Y%m%d",ValidDate)) as ValidDate,
Montantdevise,
Idevise
from {{source('fec_cerenit', 'cerenit_fec')}}
WHERE LEFT(CompteNum,1) IN ("6","7")
Ne pas oublier l’exécution du modèle pour générer la table resultat.
Troisième transformation : prévision du compte de trésorerie à 1 an
Maintentant que nous avons nos tables “bilan” et “resultat”, nous pouvons nous amuser à passer un modèle de machine learning sur le compte de trésorerie en nous appuyant sur BigQuery ML. Cela permettra de faire une projection sur l’année venir.
Pour cela, dans la même veine que précédemment, créons un modèle fec/treso_ml qui contiendra:
#fec/treso_ml.yml
version: 2
models:
- name: treso_ml
description: bq ml model to forecast treso
docs:
show: true
#fec/treso_ml.md
{% docs treso_ml %}
bq ml model to forecast treso
{% enddocs %}
et le sql assez différent du précédent :
- La partie “config” permet d’indiquer que le résultat sera un “model” et contient ensuite la configuration du modèle que nous allons appliquer
- Le modèle est créé à partir de la somme cumulative des opérations de débit/crédit sur le compte 512 et en excluant les écritures de “Report à nouveau” de début d’exercice pour ne pas les comptabiliser deux fois. En effet, nous avons 3 ans de données.
{{
config(
materialized='model',
ml_config={
'model_type': 'arima',
'time_series_timestamp_col' : 'EcritureDate',
'time_series_data_col' : 'solde',
'auto_arima' : true,
'data_frequency' : 'AUTO_FREQUENCY',
'holiday_region' : "FR"
},
post_hook="{{ dbt_ml.model_audit() }}"
)
}}
SELECT
distinct sum(Debit - Credit) OVER(ORDER BY EcritureDate) as solde,
PARSE_TIMESTAMP("%Y%m%d", EcritureDate) as EcritureDate,
FROM `datataskio.aec_fec_fec_cerenit.bilan`
WHERE Left(CompteNum,3) = "512" AND JournalCode <> "AN"
ORDER BY EcritureDate
L’exécution est plus longue (~25/30s) mais doit se faire:
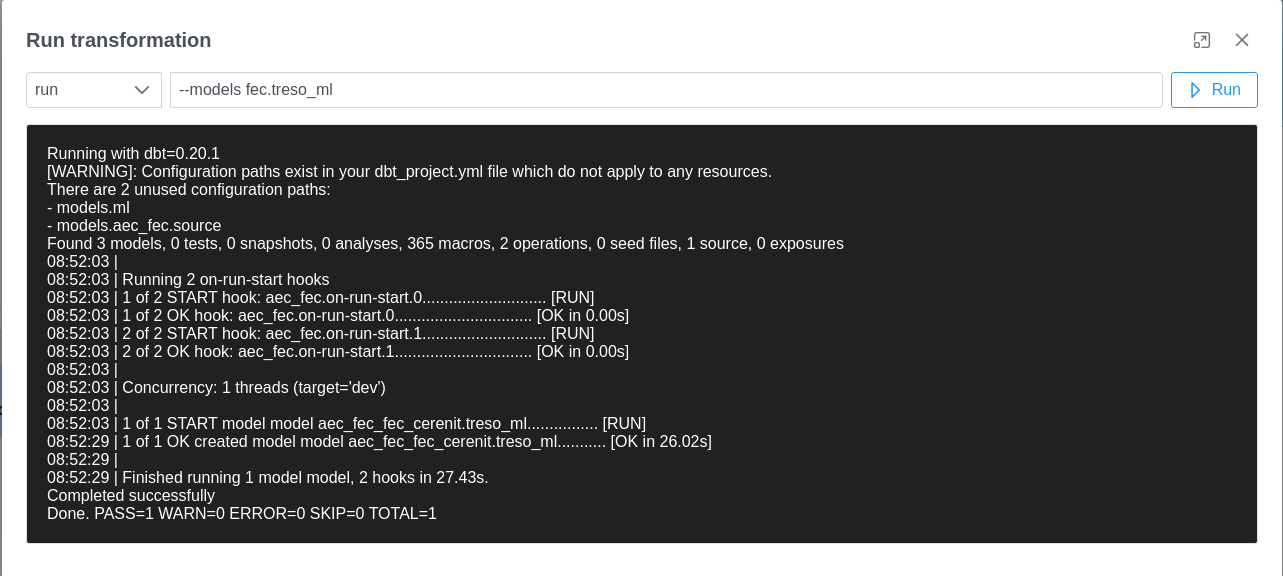
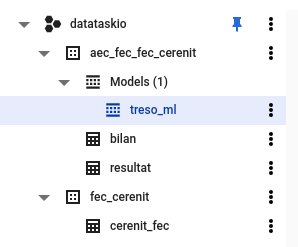
Nos transformations sont finies - nous avons ces tables et modèles dans BigQuery, prêtes pour être explorées :
Metabase
Une fois notre source de donnée BigQuery ajoutée dans Metabase, il est possible de batir les questions suivantes :
- Compte de résultat
- Compte de trésorerie annuel
- Compte de trésorerie multi-annuel
- Précision du compte de trésorerie à un an
Pour le compte de résultat, la requête est la suivante :
with
charges as (
SELECT EcritureDate, -Debit as valeur FROM `datataskio.aec_fec_fec_cerenit.resultat`
WHERE Left(CompteNum,1) = "6" AND Left(EcritureDate, 4) = {{year}} AND Debit <> 0
UNION ALL
SELECT EcritureDate, Credit as valeur FROM `datataskio.aec_fec_fec_cerenit.resultat`
WHERE Left(CompteNum,1) = "6" AND Left(EcritureDate, 4) = {{year}} AND Credit <> 0
ORDER BY EcritureDate
),
produits as (
SELECT EcritureDate, -Debit as valeur FROM `datataskio.aec_fec_fec_cerenit.resultat`
WHERE Left(CompteNum,1) = "7" AND Left(EcritureDate, 4) = {{year}} AND Debit <> 0
UNION ALL
SELECT EcritureDate, Credit as valeur FROM `datataskio.aec_fec_fec_cerenit.resultat`
WHERE Left(CompteNum,1) = "7" AND Left(EcritureDate, 4) = {{year}} AND Credit <> 0
ORDER BY EcritureDate
),
solde as (
SELECT * from charges
UNION ALL
SELECT * from produits
)
SELECT
distinct sum(valeur) OVER(ORDER BY EcritureDate) as solde,
EcritureDate,
FROM solde
ORDER BY EcritureDate
Avec la variable year, on peut alors facilement obtenir le compte de résultat de l’année souhaitée.
Nous obtenons la mise en forme suivante ; la ligne de cible de résultat et les valeurs ne sont que des options proposées par metabase :

Sur le même modèle, nous pouvons établir l’évolution du compte de trésorerie depuis la création de l’entreprise :
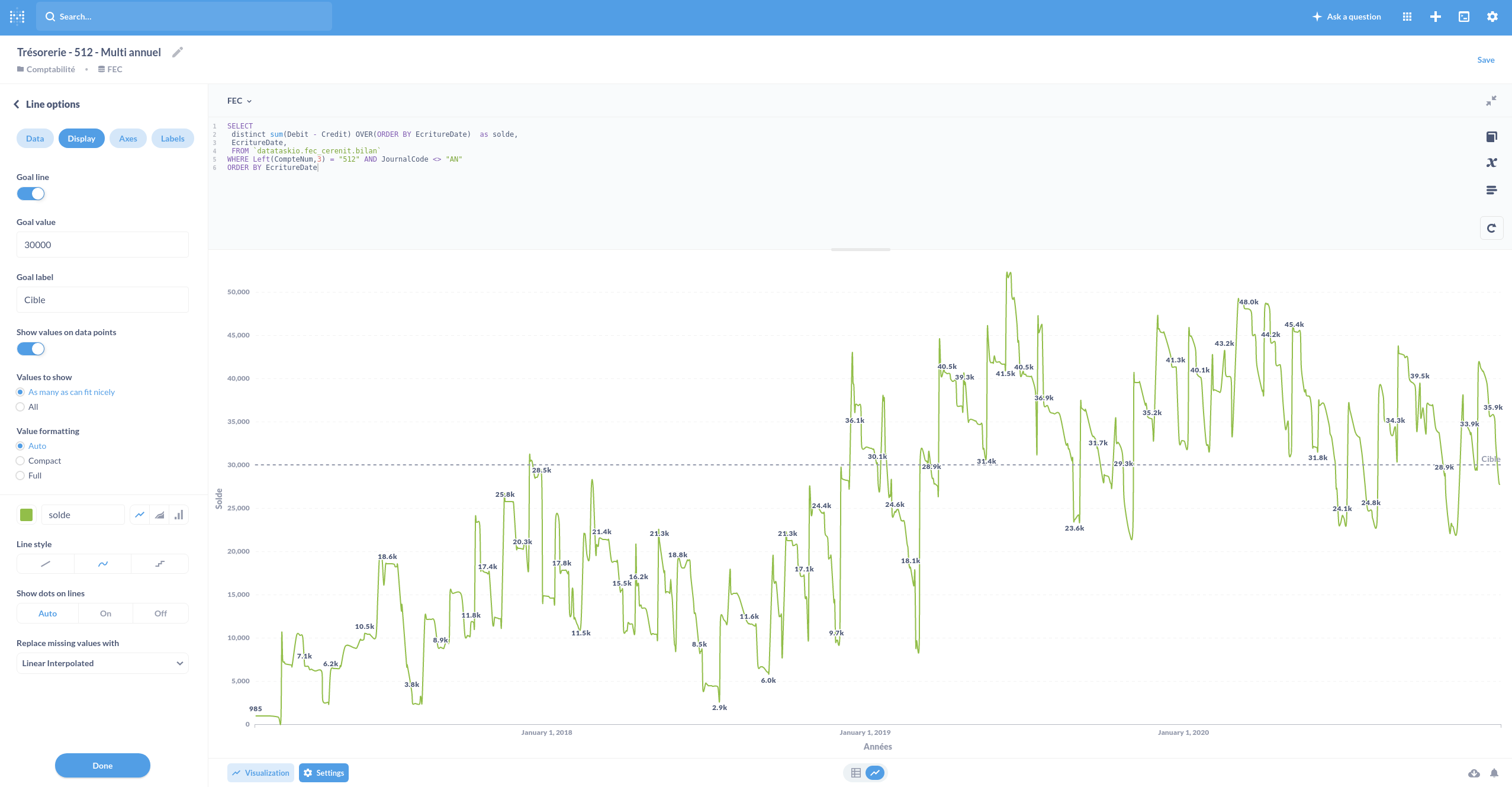
SELECT
distinct sum(Debit - Credit) OVER(ORDER BY EcritureDate) as solde,
EcritureDate,
FROM `datataskio.aec_fec_fec_cerenit.bilan`
WHERE Left(CompteNum,3) = "512" AND JournalCode <> "AN"
ORDER BY EcritureDate
et sa version annuelle :
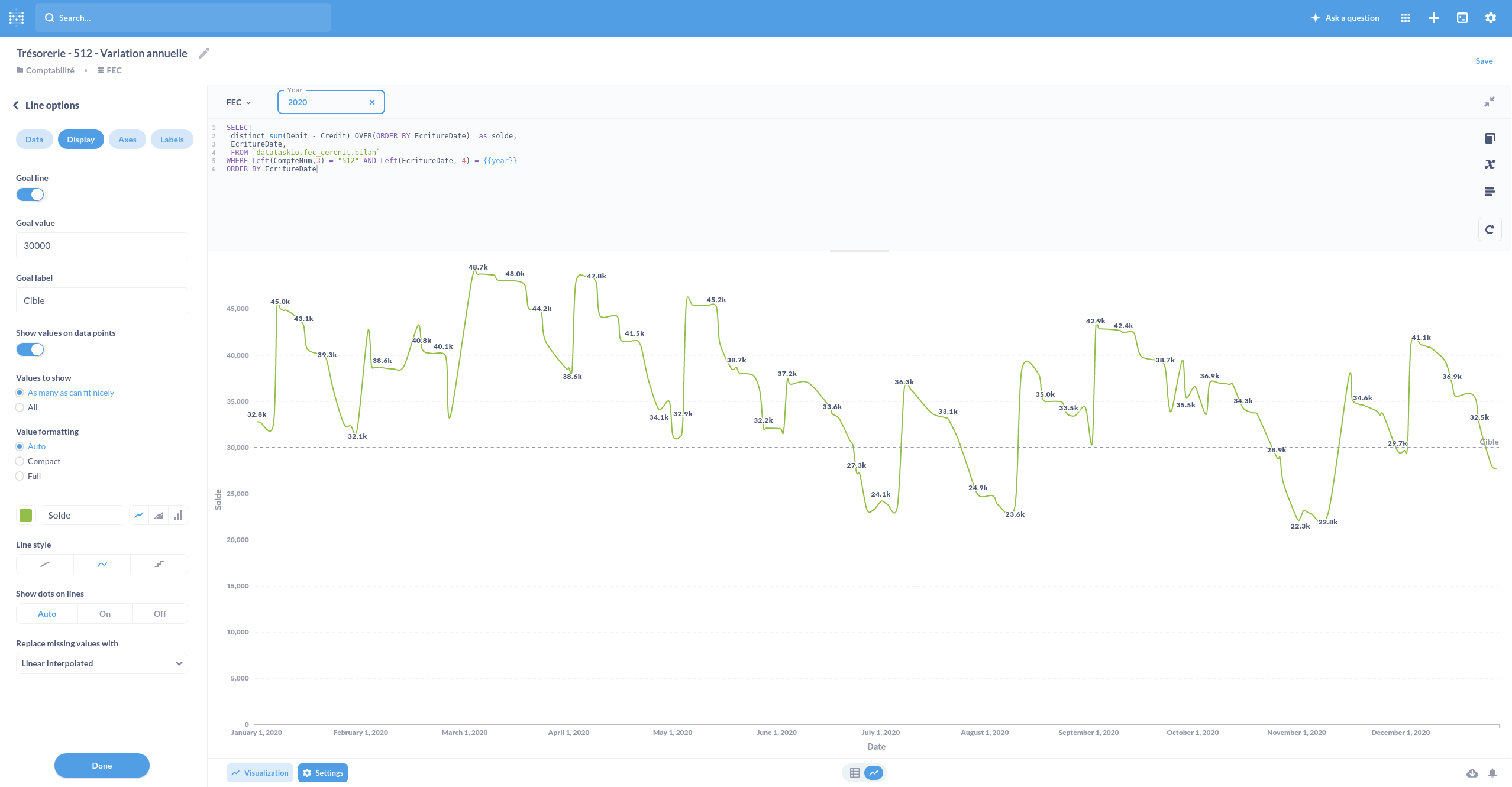
SELECT
distinct sum(Debit - Credit) OVER(ORDER BY EcritureDate) as solde,
EcritureDate,
FROM `datataskio.aec_fec_fec_cerenit.bilan`
WHERE Left(CompteNum,3) = "512" AND Left(EcritureDate, 4) = {{year}}
ORDER BY EcritureDate
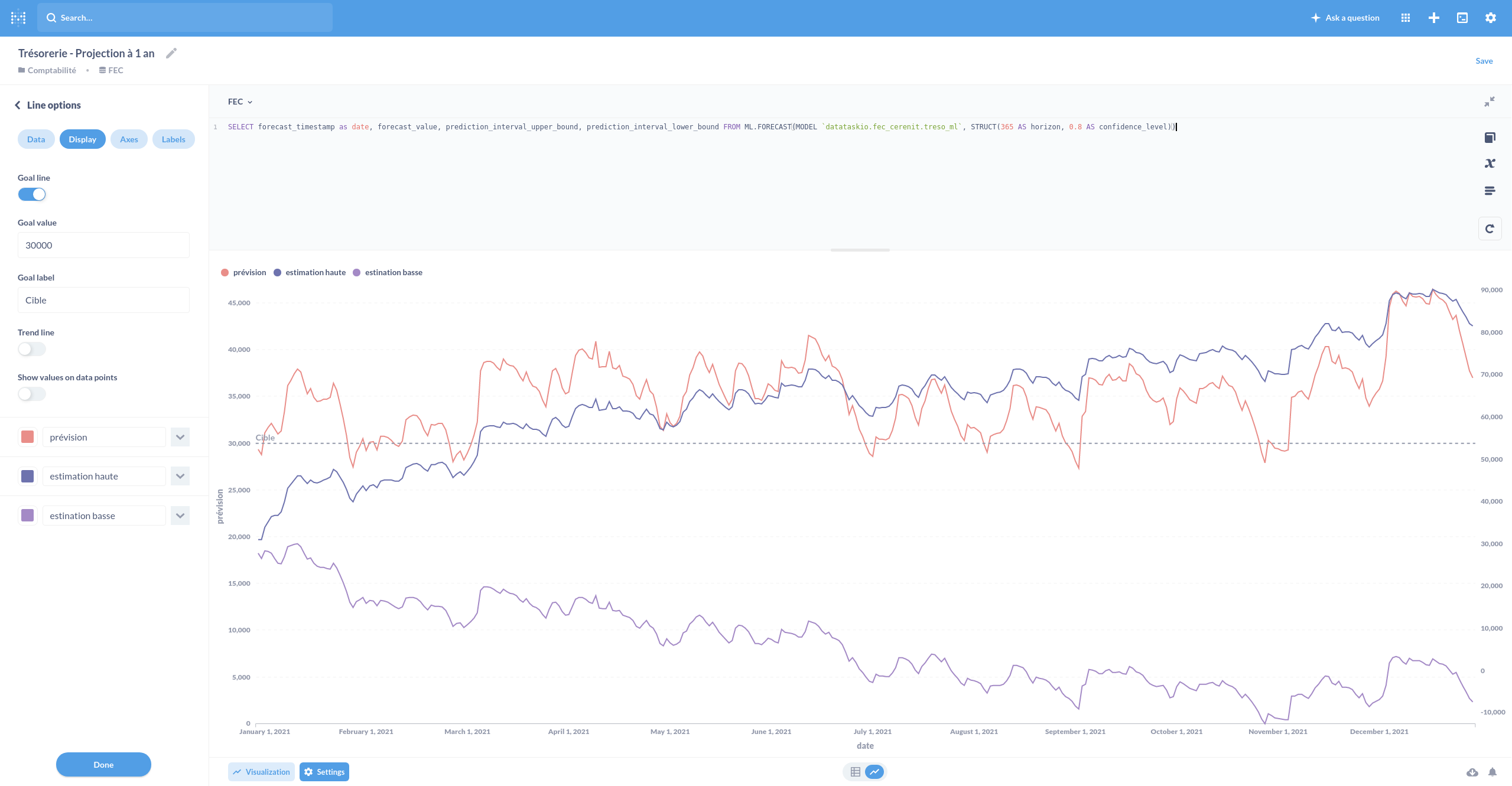
Et pour finir notre projection de trésorerie à 1 an et dont on affiche la prévision et les estimations hautes et basses :
SELECT forecast_timestamp as date, forecast_value, prediction_interval_upper_bound, prediction_interval_lower_bound FROM ML.FORECAST(MODEL `datataskio.aec_fec_fec_cerenit.treso_ml`, STRUCT(365 AS horizon, 0.8 AS confidence_level))
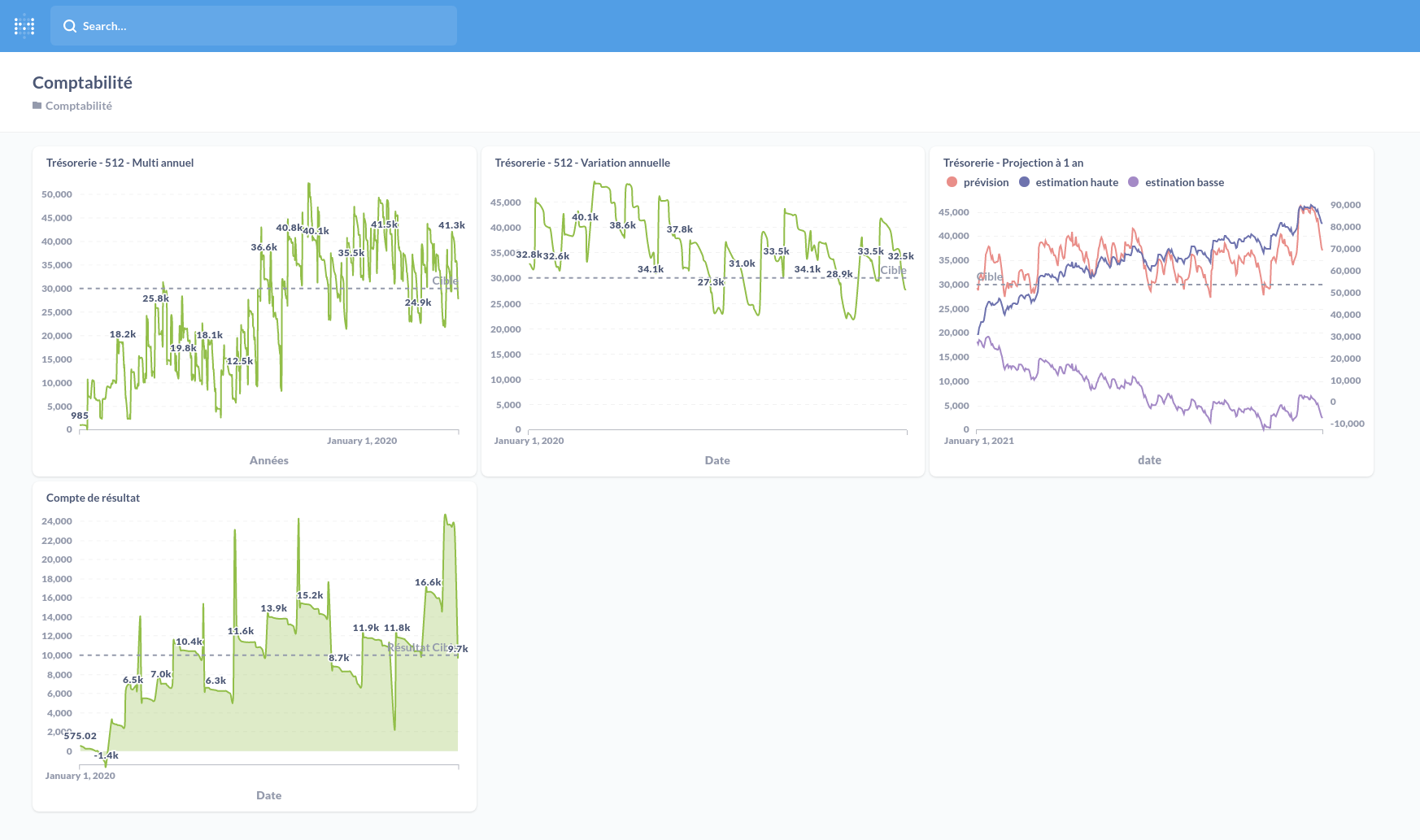
Nous pouvons rassembler cela dans un dashboard :
Conclusion
En partant des FEC et en quelques heures (en fonction de votre niveau en SQL) :
- nous les avons ingérées dans BigQuery dans un premier dataset en déclarant une connection et en décrivant un flow
- nous les avons transformées en deux tables “resultat” et “bilan” avec un reformatage de certains champs
- nous avons utilisé un modèle de machine learning disponible dans BigQuery ML pour projeter une évolution du tableau de trésorerie
- nous avons matérialisé ces données sous la forme de questions Metabase et produit un dashboard global.
N’étant pas comptable de métier et l’entreprise n’ayant pas des millions d’opérations comptables, nous nous sommes arrêtés aux aggrégats les plus simples à appréhender / calculer / analyser. Nous pourrions aller plus loin et faire des analyses plus fines avec des répartitions par clients ou fournisseurs par ex et descendre plus finement dans les classes de compte.
L’objectif étant surtout de montrer qu’il est facile pour un profil comptable d’exploiter et de mettre à disposition de ses clients les données qu’ils manipulent au quotidien.