
Lors de notre billet précédent, nous avons vu comment transformer la donnée web analytics disponible dans notre datawarehouse très simplement à l’aide d’un modèle DBT sur la plateforme Datatask. Dans ce nouveau billet, nous allons continuer l’exploration des fonctionnalités de DBT à travers l’étude d’un workflow complet de transformations. Cela va nous permettre d’aborder les notions suivantes :
- La matérialisation,
- L’exécution sélective des modèles,
- La documentation automatique.
Workflow et organisation des modèles
Les sources de données
Le point de départ de ce workflow est constitué de 2 tables sources dans bigquery events et sessions qui contiennent les données brutes relatives aux pages visitées et clics sur les sites d’affini-tech.
Dans DBT, ce type de données est appelé source et est configuré dans un fichier yaml de la manière suivante :
version: 2
sources:
- name: trkit
database: "{{ var('PROJECTID') }}"
schema: BGN5EL24
loader: trkit
tables:
- name: events
- name: sessions
Plusieurs points sont à souligner dans cet exemple :
- L’utilisation du templating jinja
{{ var('PROJECTID') }}qui permet de paramétrer le nom de la database (projet dans GCP) en utilisant la variable d’environnementPROJECTID. Cela permet, par exemple, de basculer très facilement entre différents environnements. - L’ajout d’une métadonnée
loaderpour référencer l’origine de la donnée (le process qui a permis le chargement par exemple) - La définition de plusieurs sources dans le fichier yaml : ici les 2 tables
eventsetsessions
Dans les modèles, les sources peuvent être référencées de la manière suivante :
select
EventTime as eventtime,
NULLIF(SessionID,"") as sessionid,
NULLIF(TrkitID,"") as trkitid,
Referer as referer,
UserAgent as useragent,
RemoteAddr as remoteaddr,
URL as url,
RequestURI as requesturi,
EventType as eventtype,
Data as data,
Click as click
from {{ source('trkit', 'events') }}
where
date(EventTime) >= '2020-01-01'
Organisation des modèles
L’utilisation des modèles DBT offre une très grande liberté vis à vis de l’organisation des différentes étapes de transformation. Dans notre cas, nous avons adopté une structure composée de 3 répertoires :
- “base” : transformations initiales minimales (normalisation du nom des colonnes, cast des types de données, filtres). Ce type de transformation permet de facilement prendre en compte des modifications qui auraient été apportées aux sources sans avoir à éditer l’ensemble du workflow.
- “staging” : ensemble des transformations intermédiaires
- “final” : transformations permettant d’obtenir les tables finales exploitables par des outils de reporting par exemple
L’ensemble des modèles est ainsi accessible facilement dans DataTask :
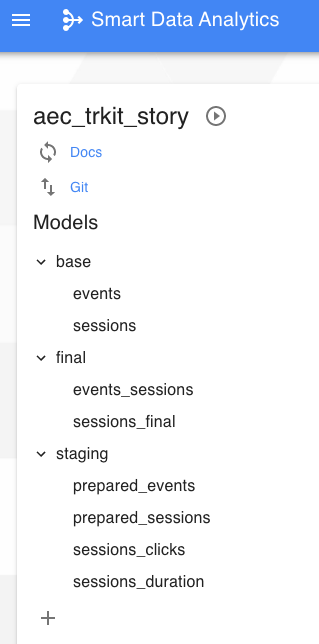
Matérialisation
Le concept de matérialisation dans dbt permet de définir la manière dont les modèles vont être “écrits” dans le datawarehouse.
Il existe 4 types de matérialisations :
- view (vue) : c’est le mode par défaut,
- table : les données sont insérées dans une table en écrasant l’existant,
- incremental : les données sont ajoutées à une table existante,
- ephemeral : pas de construction dans le datawarehouse : peu utile à mon avis.
Il est possible de modifier le comportement par défaut directement dans le modèle via la section config :
{{
config(
materialized='table',
schema='BGN5EL24_dbtworkflow',
partition_by={
"field": "eventtime",
"data_type": "timestamp",
"granularity": "day"
}
)
}}
select
ev.eventtime,
ev.sessionid,
ev.trkitid,
ev.referer,
ev.eventtype,
ev.data,
ev.click,
ev.referer_site,
ev.click_site,
se.sessionstart,
se.devicetype,
se.os,
se.browser,
se.countryname,
se.city,
se.zip,
se.latitude,
se.longitude,
se.dpt_number,
se.dpt_name,
se.region,
se.dpt_population
From {{ ref('prepared_events') }} as ev
LEFT JOIN {{ ref('prepared_sessions') }} as se
ON ev.sessionid = se.sessionid
Dans cet exemple une table sera générée dans bigquery. Il est également possible de définir d’autres paramètres : le dataset de destination, le partitionnement de la table…
Exécution sélective
La commande dbt run permet de lancer l’exécution et donc la matérialisation de l’ensemble des modèles du projet DBT dans le datawarehouse.
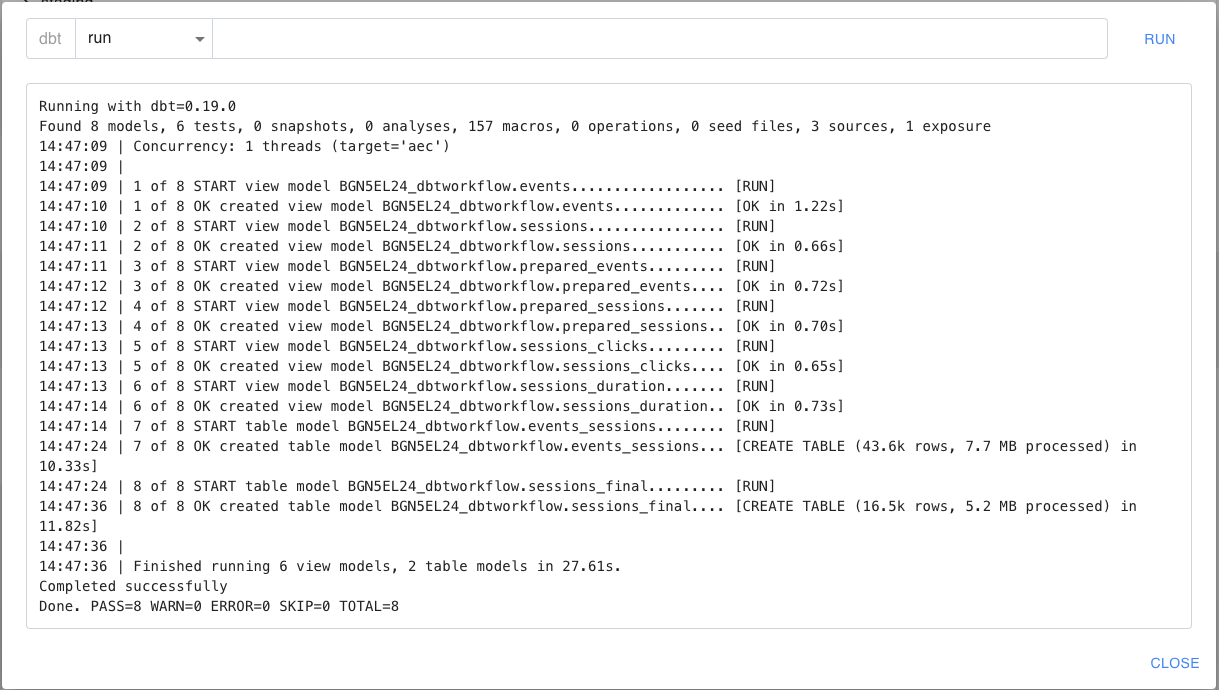
Dans notre exemple, l’ensemble du workflow comprend 8 modèles qui sont matérialisés (6 en vues et 2 en tables).
Cependant, il est souvent utile de limiter l’exécution et de ne pas systématiquement lancer une exécution complète (en phase de développement d’un modèle par exemple). Pour cela DBT dispose de plusieurs moyens de sélection pour s’adapter à chaque situation :
- modèle spécifique avec l’option
--models(ou-m) - opérateurs de graphe :
+,*,@ - unions et intersections
- critères de méthodes :
tag,source,config, etc.
L’opérateur de graphe + est très souvent utilisé car il permet d’exécuter un modèle et ses dépendances. En effet, l’utilisation dans les modèles de la syntaxe {{ ref('*model_name*') }} permet au système de construire un DAG (graphe de dépendances). L’opérateur + permet alors de selectionner :
- soit un modèle et tous les modèles parents avec l’opérateur devant le nom du modèle,
- soit un modèle et tous les modèles enfants avec l’opérateur après le nom du modèle.
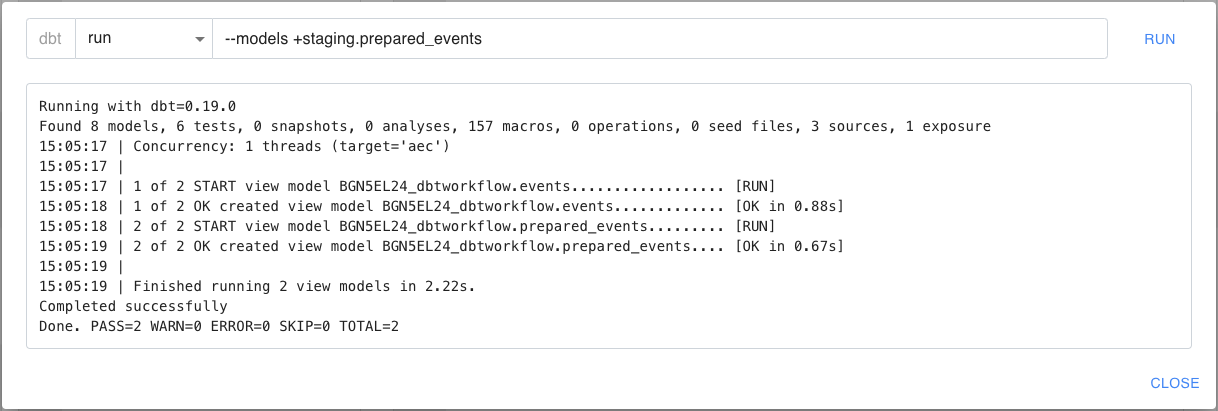
Ici le système ne matérialise que 2 modèles : celui directement sélectionné par l’option --models (prepared_events) et son parent (events).
Il est possible également de poser des tags sur les modèles et de faire ensuite une selection par tag. Par exemple : dbt run --models tag:projetX permettra de matérialiser tous les modèles portant un tag “projetX”.
Documentation du workflow
D’un point de vue de la gouvernance des données, il est indispensable de bien documenter les workflows et les tables/vues générées aux différentes étapes. Ce processus peut parfois être difficile à mettre en place et à maintenir Heureusement, DBT va permettre de gérer cette aspect et la plateforme DataTask va assurer la plublication de la documentation générée.
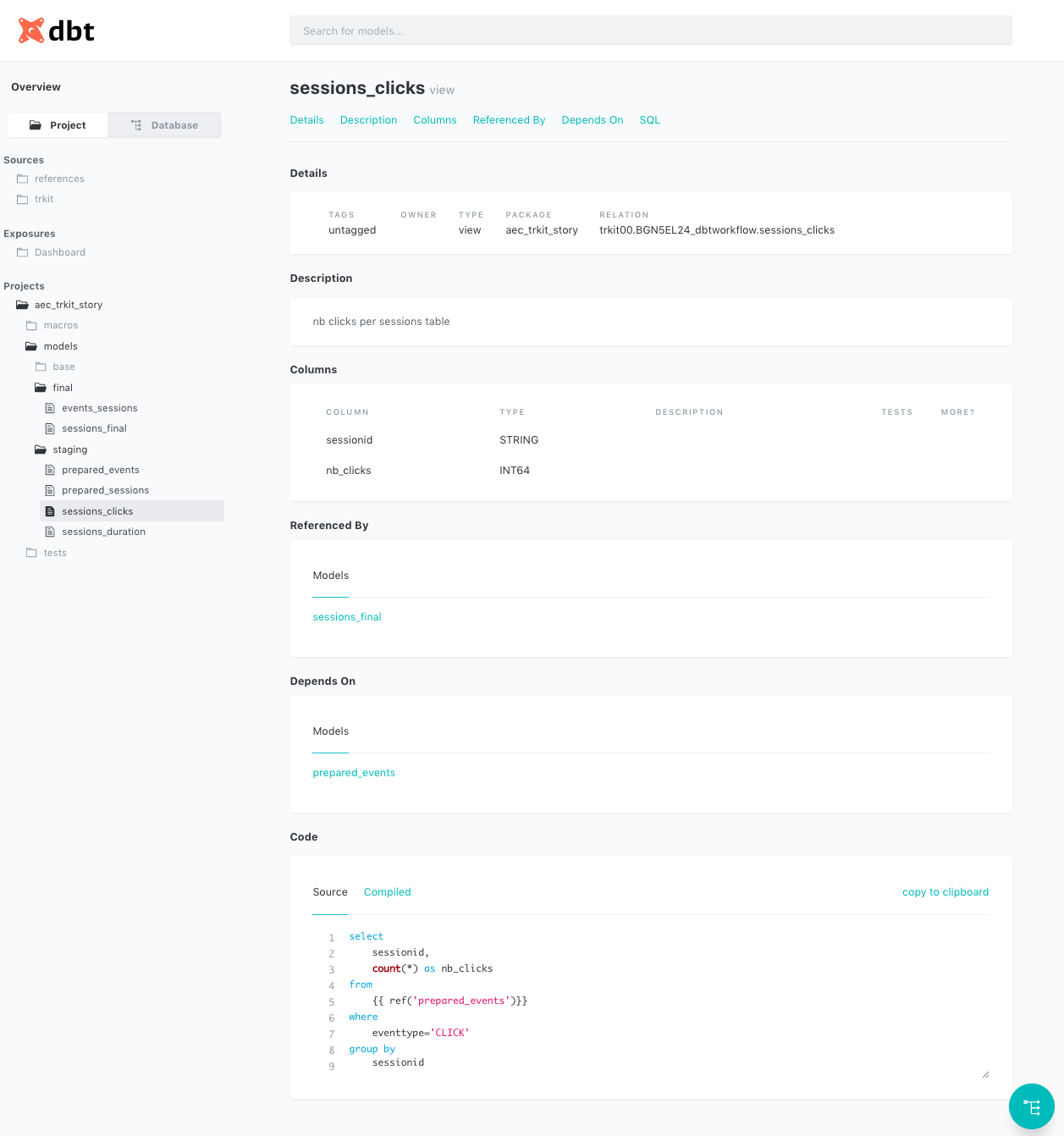
Par défaut, DBT permet de génrer automatiquement une documentation minimale qui va répertorier l’ensemble des objets (modèles, sources, tests, macros…) et leurs métadonnées (emplacement, taille, colonnes…) ainsi que leurs dépendances.
Les dépendances peuvent être visualisées sous forme de graphe. Il est alors possible d’avoir un accès immédiat au lineage du workflow complet.
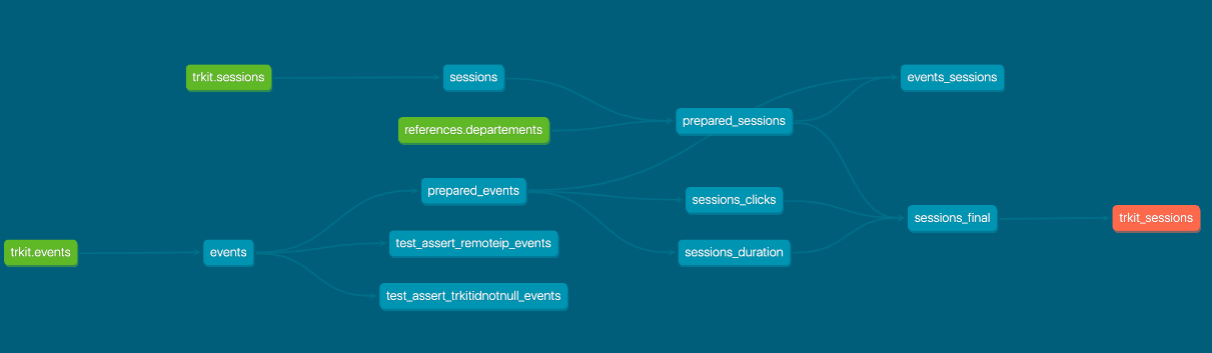
La documentation par défaut peut également être enrichie en éditant le fichier yaml associé au modèle.
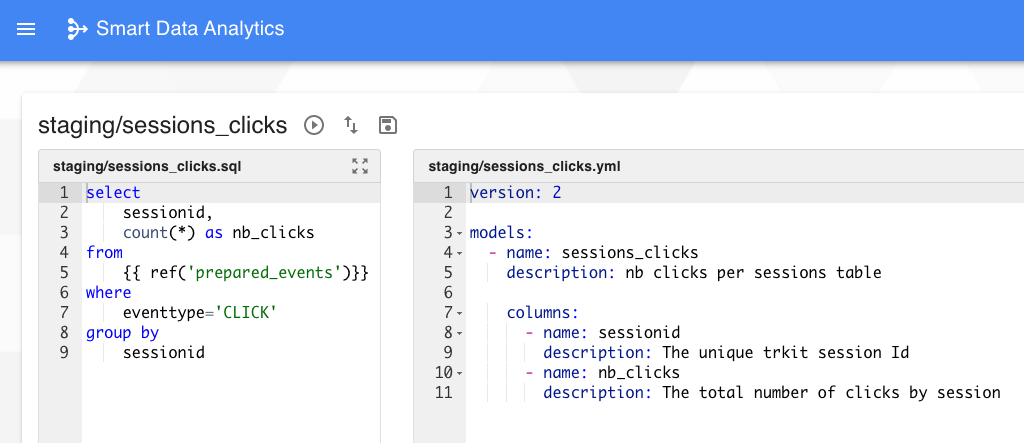
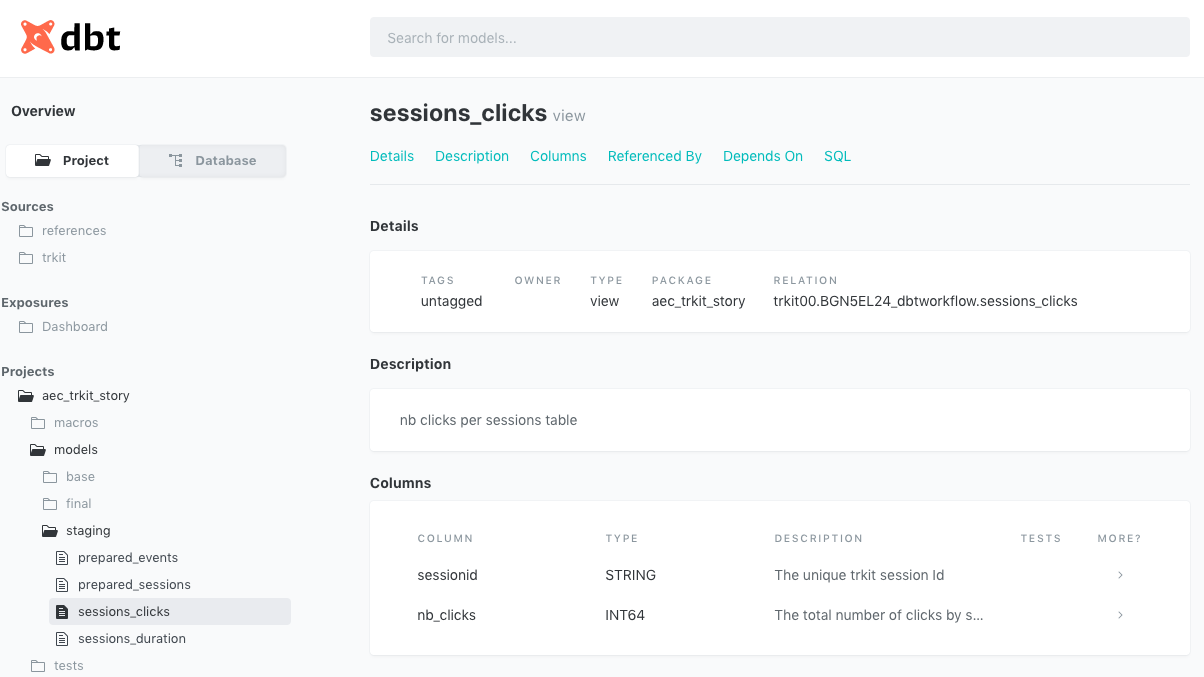
Dans cet exemple, une description a été ajouté au niveau du modèle ainsi que pour chaque colonne. On retrouve alors ces informations dans la documentation générée :
Conclusion
Dans ce billet et le précédent, nous avons vu avec quelle facilité DBT et la plateforme DataTask permettent de mettre en place un workflow complet de transformation de données ainsi que l’ensemble de la documentation associée. Dans la prochaine publication, je vous présenterai l’outil de reporting et d’exploration Metabase (également intégré à la plateforme DataTask). Metabase va permettre l’exploitation de cette donnée raffinée ainsi que la mise à disposition aux utilisateurs.
Ce billet fait partie d’une série :
- DataTask pour construire une self-service BI
- Une revue des principaux concepts de dbt et création d’un premier modèle dans DataTask (ce billet)
- L’étude du workflow de transformation complet via DBT ainsi que la présentation de la documentation automatique associée
- Une revue rapide des principales fonctionnalités de Metabase, et plus particulièrement la création d’un dashboard d’analyse automatique, son édition et sa sauvegarde pour publication
- L’utilisation de fonctionnalités supplémentaires de DBT pour améliorer la gouvernance autour de la donnée : la création de tests sur la donnée et documentation de lineage à travers les exposures
- La mise en place d’un pipeline DataTask de manière à assurer la mise à jour automatique des données au cours du temps