Etape 1 : Préparation du job
En premier lieu se connecter sur la plateforme DataTask (https://apps.datatask.io/authentication/login), soit avec le couple user/password soit via son compte google (celui utilisé pour l’inscription).
Une fois connecté à la plateforme, on arrive sur le portail donnant accès aux applications déployées. On se rend sur le JupyterLab en cliquant sur l’icone correspondante.

Une fois dans le JupyterLab nous allons procéder à la préparation de notre projet :
Cloner le repo git http://apps.datatask.io/git/ORGANISATION_GIT/quickstart-data-tpch à partir du module git de JupyterLab.
| Remplacer ORGANISATION_GIT par le nom de votre organisation sur git. |
Via l’explorateur de fichier, accéder au dossier qs-load-customer contenu dans le dossier quickstart-data-tpch. Ce dossier contient un code qui va charger un dataset situé dans un bucket GCP dans une base BigQuery.
La structure du dossier, constituée d’un fichier manifest.json à la racine et d’un dossier code qui contient un Dockerfile et un ou plusieurs fichiers contenant du code (du python dans notre cas) est celle utilisée par défaut par les tasks s’exécutant sur Datatask.
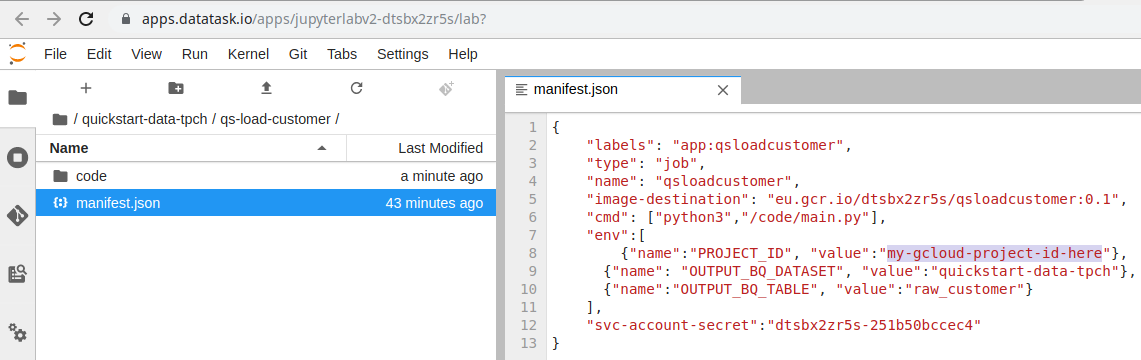
Ouvrir le fichier manifest.json (clic droit → Open With → Editor). C’est ce fichier qui contient la configuration du job. Nous allons remplacer la valeur de variable d’environnement PROJECT_ID qui est my-gcloud-project-id-here par l’identifiant de notre projet GCP afin que l’output du traitement arrive bien dans notre base BigQuery.
Une fois ceci effectué, toujours avec le module git de JupyterLab, commiter et pousser les modifications afin de mettre à jour le repo git.