Etape 4 : Préparation et déploiement du pipeline
Sur Datatask, un pipeline se définit par un ensemble de jobs dont l’exécution est orchestrée. Nous allons procéder au déploiement du pipeline suivant :
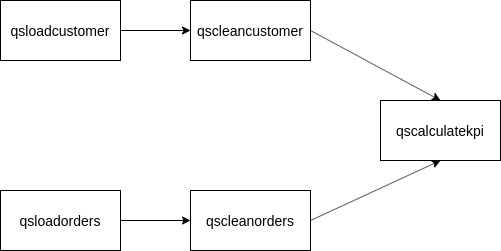
| Le job qsloadcustomer correspond au job que nous avons configuré et déployé précédemment. Meme si nous l’avons déjà exécuté, il a été configuré de manière à ré-écraser les données de la table BigQuery afin de ne pas les dupliquer. |
Ici, notre pipeline est composé de 5 jobs, dont l’ordre d’exécution est définit par le sens des flèches, l’input de chaque job suivant dépend de l’output du job précédent.
Dans le menu principal en haut à gauche, on clique cette fois-ci sur Tasks → New Pipeline.
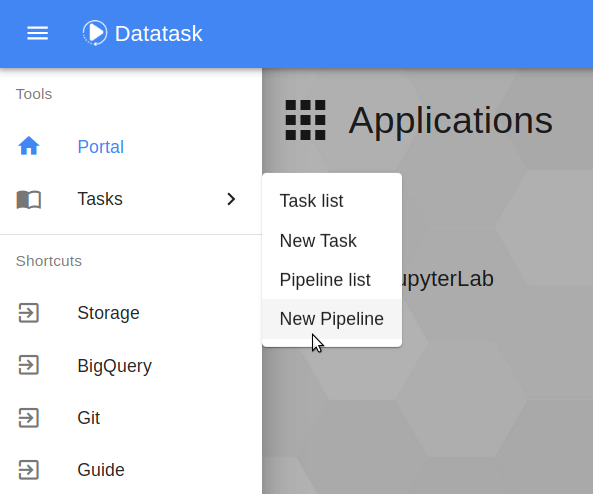
On arrive sur une page similaire à celle de création de job, le principe reste le même que la création d’un job. Dans le champ Directory, on indiquera ici le dossier contenant le pipeline à exécuter: qs-kpi-pipeline (pour le champ Repository on met comme précédemment quickstart-data-tpch). Puis on clique sur Load pour charger le pipeline.
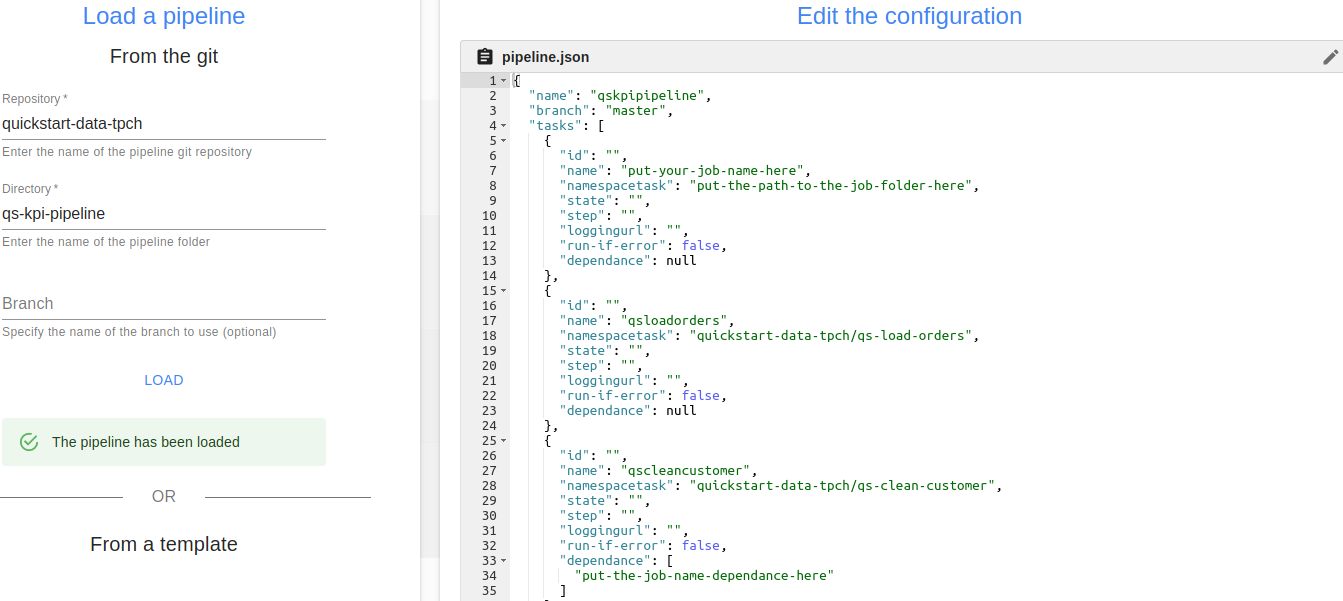
Comme pour les job, le fichier de configuration du pipeline s’affiche, en l’occurence il s’agit du fichier pipeline.json. Cette fois-ci, nous allons modifier ce fichier via l’interface afin que le pipeline s’exécute correctement. Il nous faut pour cela modifier les placeholder liés au job qsloadcustomer dans 3 endroits précis :
| Les noms de job DataTask ne peuvent contenir que des caractères alphanumériques en minuscule. |
-
On commence par donner un nom à ce job. On remplace "put-your-job-name-here" par "qsloadcustomer".
-
Ensuite, on renseigne le chemin du dossier correspondant à ce job (en prenant comme base la racine du repo git). On remplace "put-the-path-to-the-job-folder-here" par "quickstart-data-tpch/qs-load-customer"
-
Pour finir, pour indiquer que le job qscleancustomer dépend du job qsloadcustomer on remplace "put-the-job-name-dependance-here") par "qsloadcustomer".
On n’oublie pas de cliquer sur la coche en haut à droite de la zone d’édition du pipeline.json pour valider les modifications. On sélectionne ensuite le namespace dans lequel le pipeline va s’exécuter, dans notre cas dtsbx2zr5s et on clique sur RUN pour déployer le pipeline.
On peut suivre la progression de notre pipeline en cliquant sur follow the progress. Au début on voit que les jobs qsloadcustomer et qsloadorders s’éxécutent en parallèle (la couleur bleu signifie "en cours d’éxécution")
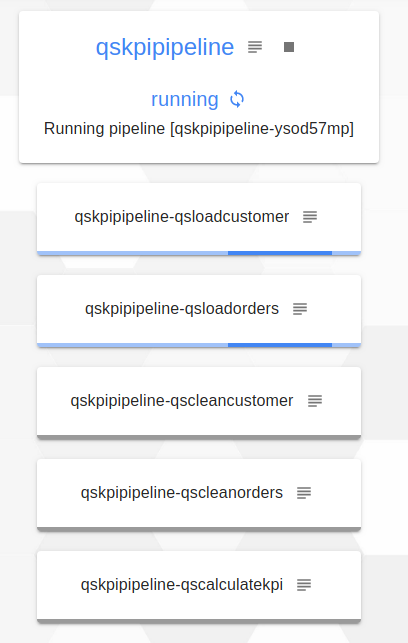
Puis, on voit que le job qsloadorders est terminé (il est en vert), donc le job qscleanorders qui dépendait de ce dernier est en cours d’éxécution.
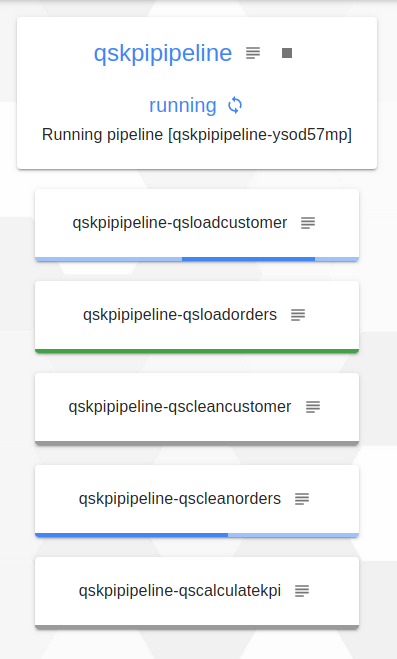
Enfin, quand le pipeline est terminé tous les jobs sont en vert et sous le nom du pipeline il est indiqué completed.
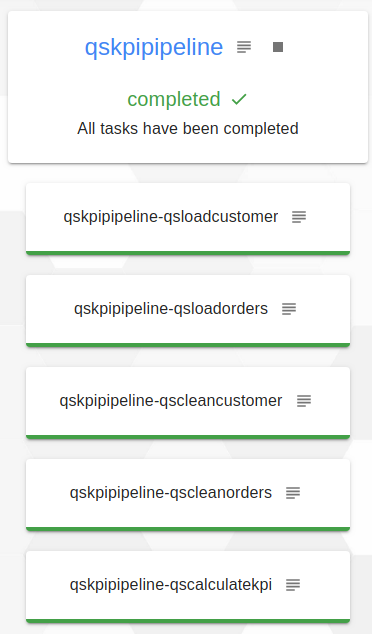
Une fois l’exécution du pipeline terminée, nous allons maintenant passer au déploiement de notre dernier composant, le service de dashboard de visualisation des KPI.