Step 4 : Preparation and deployment of the pipeline
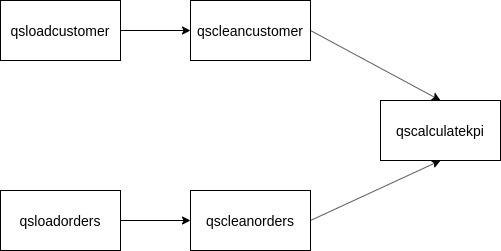
On Datatask, a pipeline is defined by a set of jobs whose execution is orchestrated. We will proceed with the deployment of the following pipeline:
| The qsloadcustomer job is the job we have configured and deployed previously. Even if we have already run it, it has been configured to overwrite data in the BigQuery table so as not to duplicate it. |
Here, our pipeline is composed of 5 jobs, whose order of execution is defined by the direction of the arrows, the input of each following job depends on the output of the previous job.
In the main menu at the top left, this time we click on Tasks → New Pipeline.
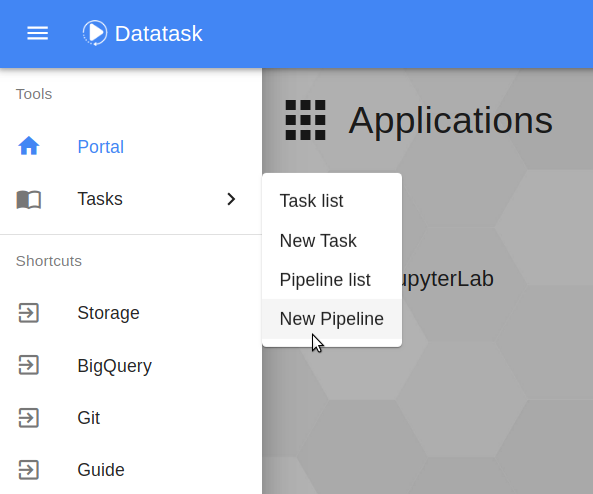
We arrive on a page similar to the job creation page, the principle remains the same as the creation of a job. In the Directory field, we will indicate here the folder containing the pipeline to be executed: qs-kpi-pipeline (for the Repository field we put as above quickstart-data-tpch). Then click on Load to load the pipeline.
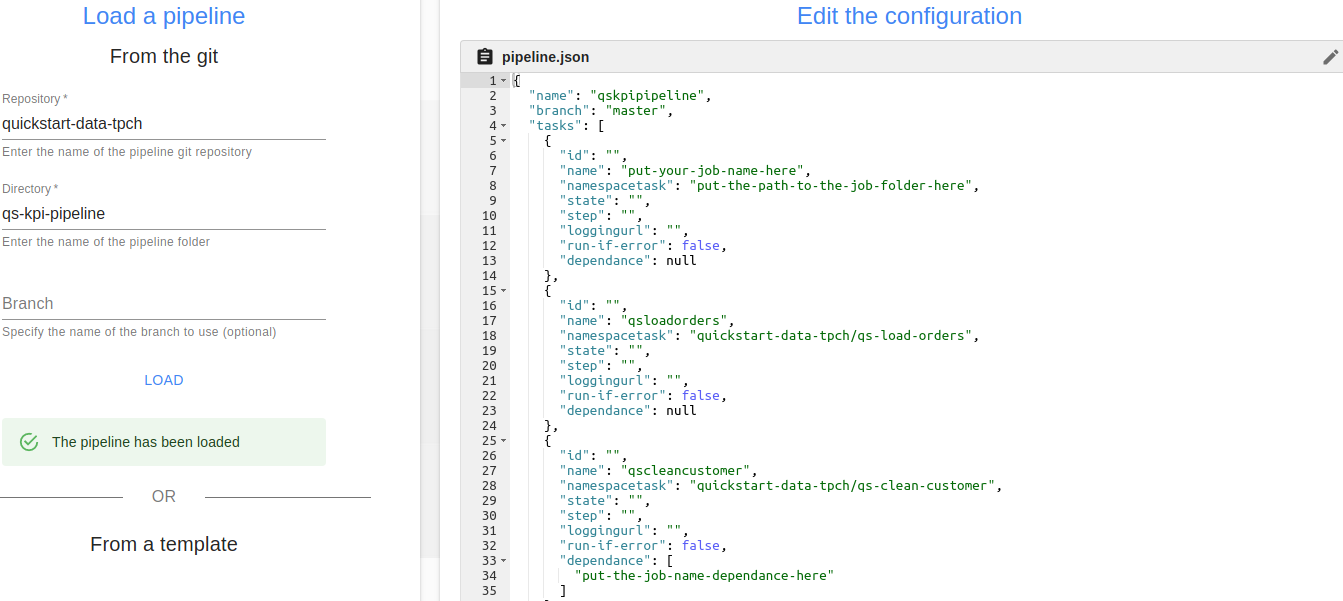
As for the jobs, the pipeline configuration file is displayed, in this case it is the pipeline.json file. This time, we will modify this file via the interface so that the pipeline runs correctly. To do this we need to modify the placeholders linked to the qsloadcustomer job in 3 places :
| DataTask job names can only contain lowercase alphanumeric characters. |
-
We start by giving a name to this job. Replace "put-your-job-name-here " by "qsloadcustomer ".
-
Then, we fill in the path of the folder corresponding to this job (based on the root of the repo git). Replace "put-the-path-to-the-job-folder-here " with "quickstart-data-tpch/qs-load-customer ".
-
Finally, to indicate that the qscleancustomer job depends on the qsloadcustomer job, we substitute "put-the-job-name-dependence-here ") by "qsloadcustomer ".
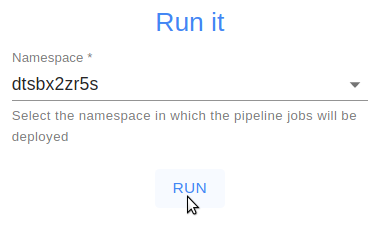
Don’t forget to click on the check mark in the top right corner of the pipeline.json editing area to validate the modifications. Then, we select the namespace in which the pipeline will run, in our case dtsbx2zr5s and we click on RUN to deploy the pipeline.
You can follow the progress of our pipeline by clicking on follow the progress. At the beginning we see that the qsloadcustomer and qsloadorders jobs run in parallel (blue color means "in progress").
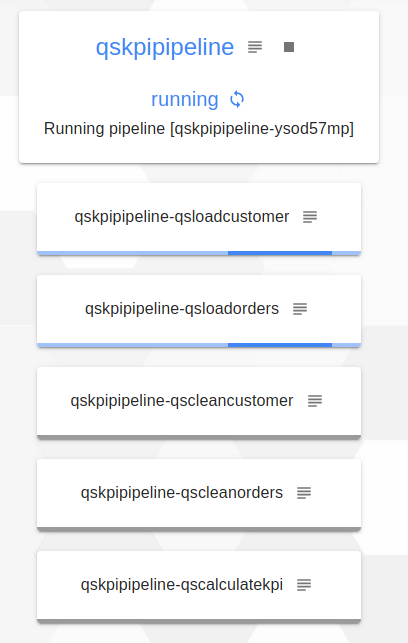
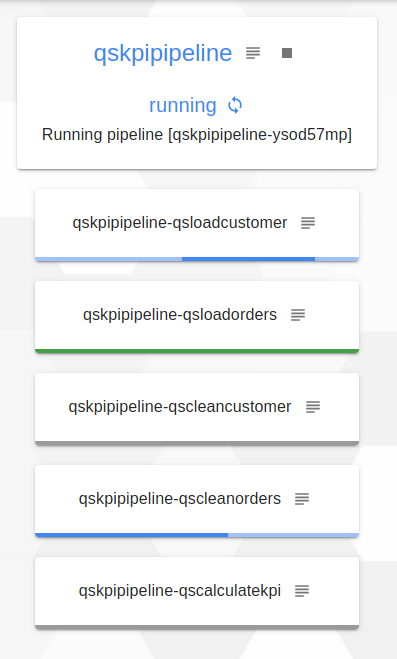
Then, we see that the qsloadorders job is finished (it is in green), so the qscleanorders job which depended on the latter is currently being executed.
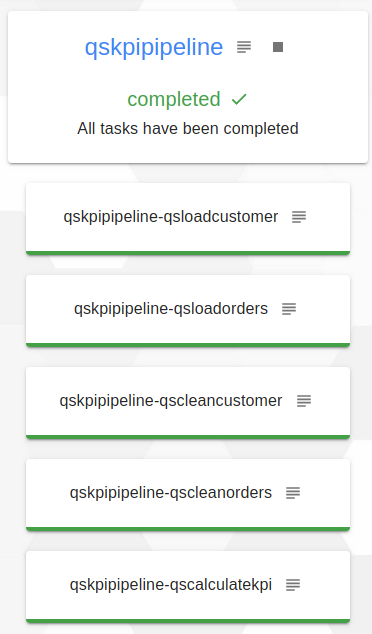
Finally, when the pipeline is finished, all jobs are in green and under the pipeline name it is indicated completed.
Once the execution of the pipeline is complete, we will now move on to the deployment of our last component, the KPI dashboard visualization service.